eBPF简介
BFP
BPF 全名为 BSD Packet Filter,最初被应用于网络监测,例如知名的TCPdump 工具中,它可以在内核态根据用户定义的规则直接过滤收到的包,相较竞争者 CSPF 更加高效
它设计了一个基于寄存器的虚拟机用来过滤包,而 CSPF 则使用的是基于栈的虚拟机
BPF 有两个组成部分:
- Tap 部分负责收集数据
- Filter 部分负责按规则过滤包
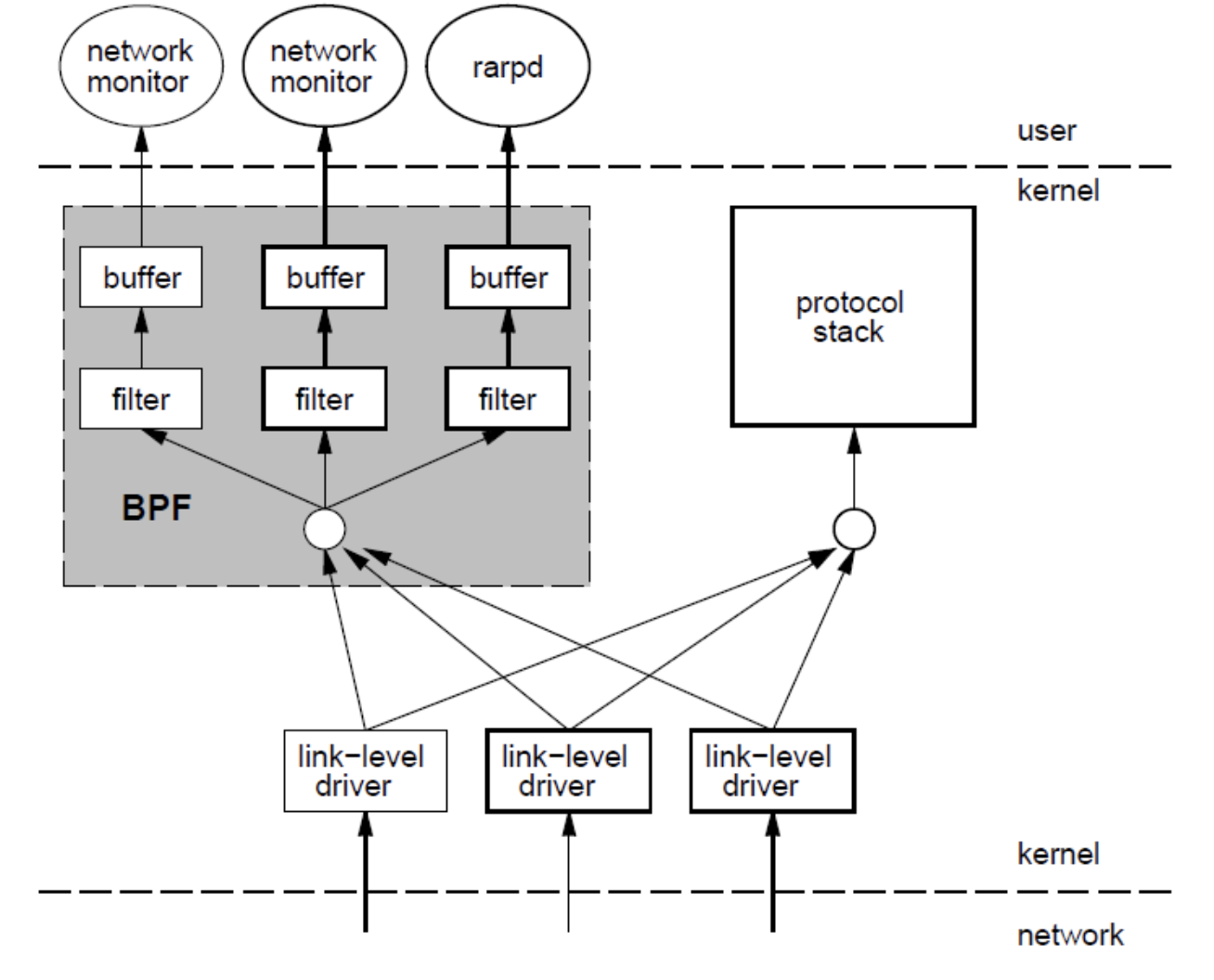
收到包以后,驱动不仅会直接发给协议栈,还会发给 BPF 一份, BPF根据不同的filter直接“就地”进行过滤,不会再拷贝到内核中的其他 buffer 之后再就行处理,否则就太浪费资源了。处理后才会拷贝需要的部分到用户可以拿到的 buffer 中,用户态的应用只会看到他们需要的数据
注意在 BPF 中进行处理的时候,不是一个一个包进行处理的,因为接收到包之间的时间间隔太短,使用 read 系统调用又是很费事的,所以 BPF 都是把接收到的数据打包起来进行分析,为了区分开这些数据,BPF 会包一层首部(header),用来作为数据的边界
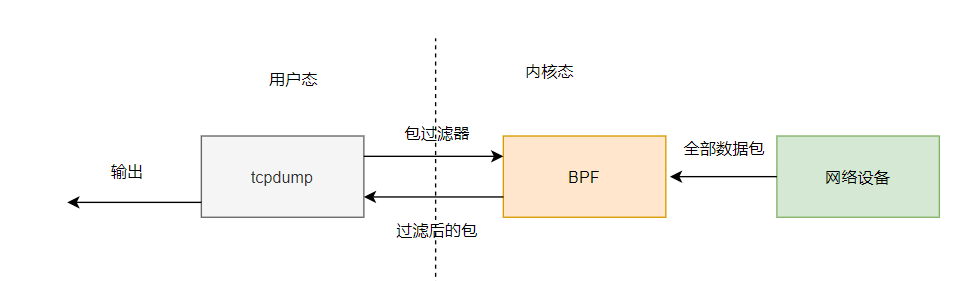
经典的 BPF 的工作模式是用户使用 BPF 虚拟机的指令集定义过滤表达式,传递给内核,由解释器运行,使得包过滤器可以直接在内核态工作,避免向用户态复制数据,从而提升性能,比如 tcpdump 的 BPF 过滤指令实例如下:
> tcpdump -d port 80
(000) ldh [12]
(001) jeq #0x86dd jt 2 jf 10
(002) ldb [20]
(003) jeq #0x84 jt 6 jf 4
(004) jeq #0x6 jt 6 jf 5
(005) jeq #0x11 jt 6 jf 23
(006) ldh [54]
(007) jeq #0x50 jt 22 jf 8
(008) ldh [56]
(009) jeq #0x50 jt 22 jf 23
(010) jeq #0x800 jt 11 jf 23
(011) ldb [23]
(012) jeq #0x84 jt 15 jf 13
(013) jeq #0x6 jt 15 jf 14
(014) jeq #0x11 jt 15 jf 23
(015) ldh [20]
(016) jset #0x1fff jt 23 jf 17
(017) ldxb 4*([14]&0xf)
(018) ldh [x + 14]
(019) jeq #0x50 jt 22 jf 20
(020) ldh [x + 16]
(021) jeq #0x50 jt 22 jf 23
(022) ret #262144
(023) ret #0
执行过程如下:
Linux 3.0 中增加了JIT(即时编译),性能比解释执行更快,类似 java 的虚拟机,可以解释执行也可以即时编译执行
现在 BPF 的执行过程如下示意图:
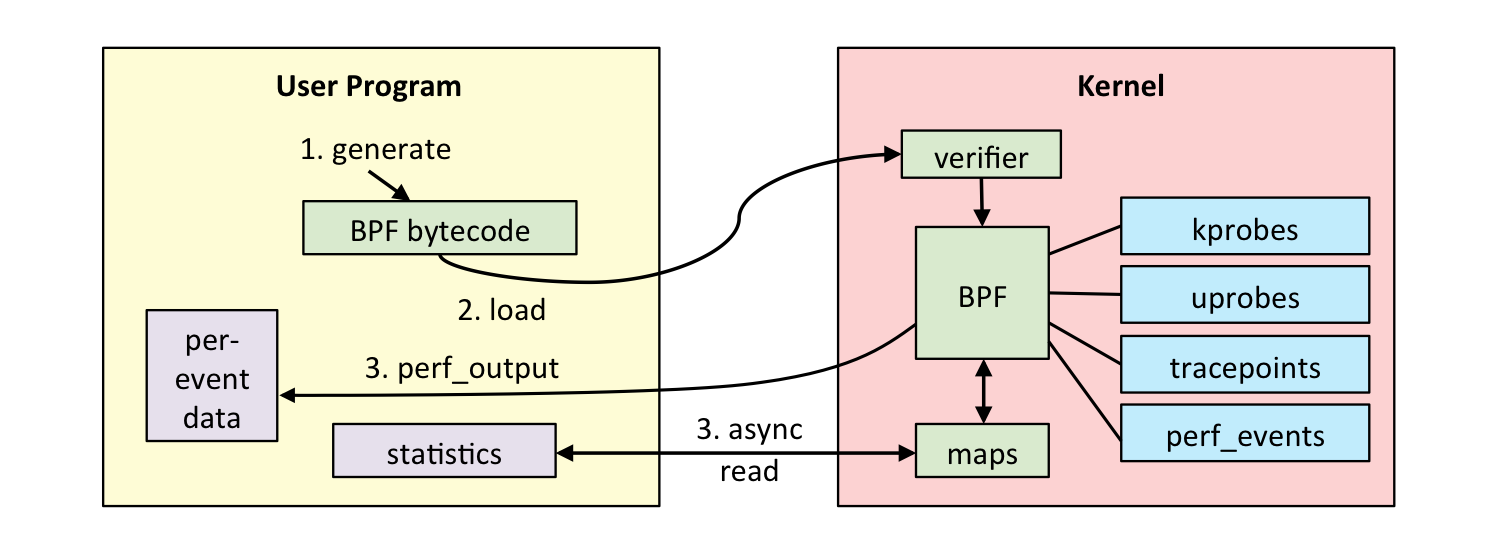
(1)编写 eBPF 代码
(2)将 eBPF 代码通过 LLVM 把编写的 eBPF 代码转成字节码
(3)通过 bpf 系统调用提交给系统内核
(4)内核通过验证器对代码做安全性验证(包括对无界循环的检查)
(5)只有校验通过的字节码才会提交到 JIT 进行编译成可以直接执行的机器指令
(6)当事件发生时候,调用这些指令执行,将结果保存到 map 中
(7)用户程序通过映射来获取执行结果
eBPF
eBPF (extended BPF)
对于算法和数据结构应该大家都不陌生,在这门学科的语境里用 O(xxx)来衡量算法的复杂度。但是实际的工作中性能工程师要回答的常常不是时间复杂度问题,而是
- 程序的哪个部分慢?
- 慢的部分,单次执行的耗时是多少?
eBPF 能在不改一行代码的情况下,知道给定函数单次执行的耗时,并且是纳秒级别的精度。
官方:
Linux 内核一直是实现监控/可观测性、网络和安全功能的理想环境。 不过很多情况下这并非易事,因为这些工作需要修改内核源码或加载内核模块, 最终实现形式是在已有的层层抽象之上叠加新的抽象。 eBPF 是一项革命性技术,它能在内核中运行沙箱程序(sandbox programs), 而无需修改内核源码或者加载内核模块。
将 Linux 内核变成可编程之后,就能基于现有的(而非增加新的)抽象层来打造更加智能、 功能更加丰富的基础设施软件,而不会增加系统的复杂度,也不会牺牲执行效率和安全性。
原理
进程运行在操作系统(kernel)之上,也就是说进程干了什么,现在在干什么操作系统是清清楚楚的。
这样的话!问题 2 的解决方案就变成了告诉操作系统,让它帮忙盯一下给定函数在什么时候开始执行,并且什么时候执行完成。我们只要拿到这两个时间点就能算出特定函数单次执行的耗时。
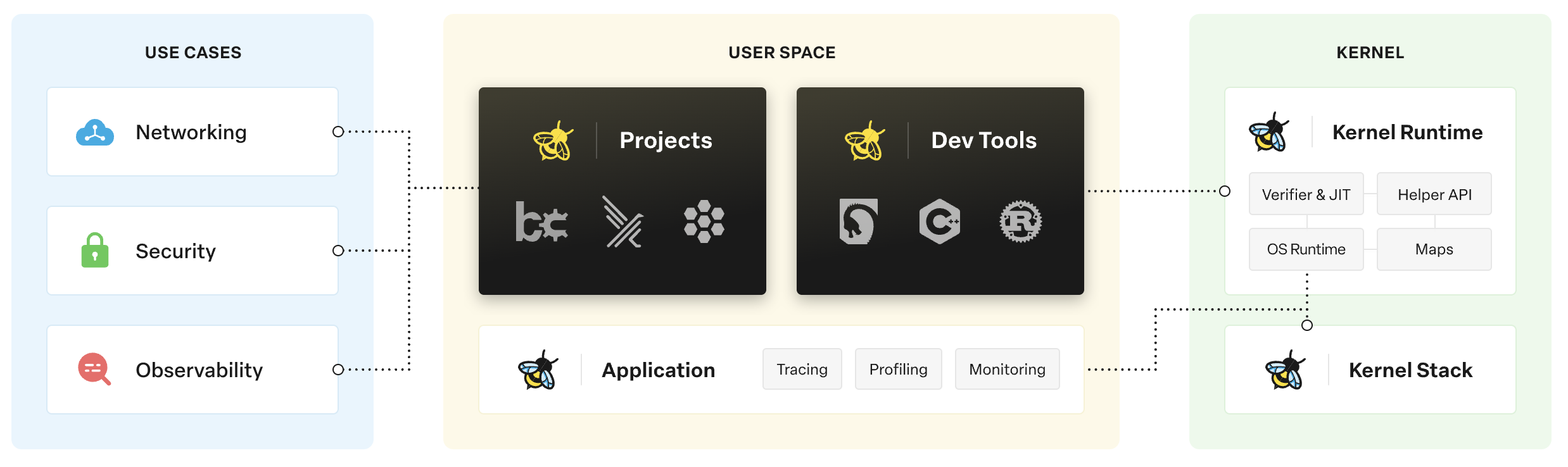
那我们怎么才能告诉操作系统呢?
Linux 内核里面有一个叫 eBPF 的框架,它是我们与内核对话的接口人。我们使用一门叫 bpftrace 的语言就可以和它对话,把我们想要做的事情告诉它。
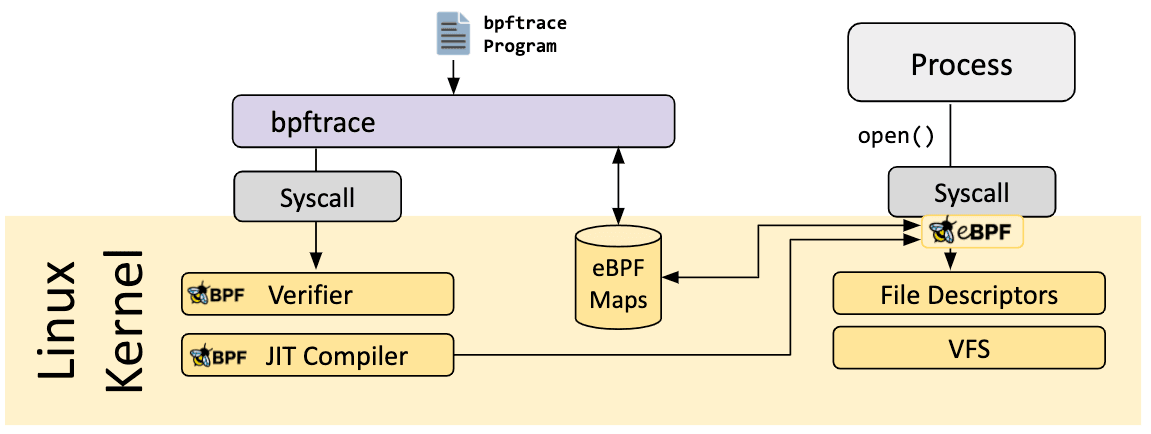
eBPF 的整体的架构如下: