Go编译器简介
Go 编译器
编译器是一个大型且复杂的系统,一个好的编译器会很好地结合形式语言理论、算法、人工智能、系统设计、计算机体系结构及编程语言理论
Go语言的编译器遵循了主流编译器采用的经典策略及相似的处理流程和优化规则(例如经典的递归下降的语法解析、抽象语法树的构建)
另外,Go 语言编译器有一些特殊的设计,例如内存的逃逸等
三阶段编译器
在经典的编译原理中,一般将编译器分为
- 编译器前端
- 优化器
- 编译器后端
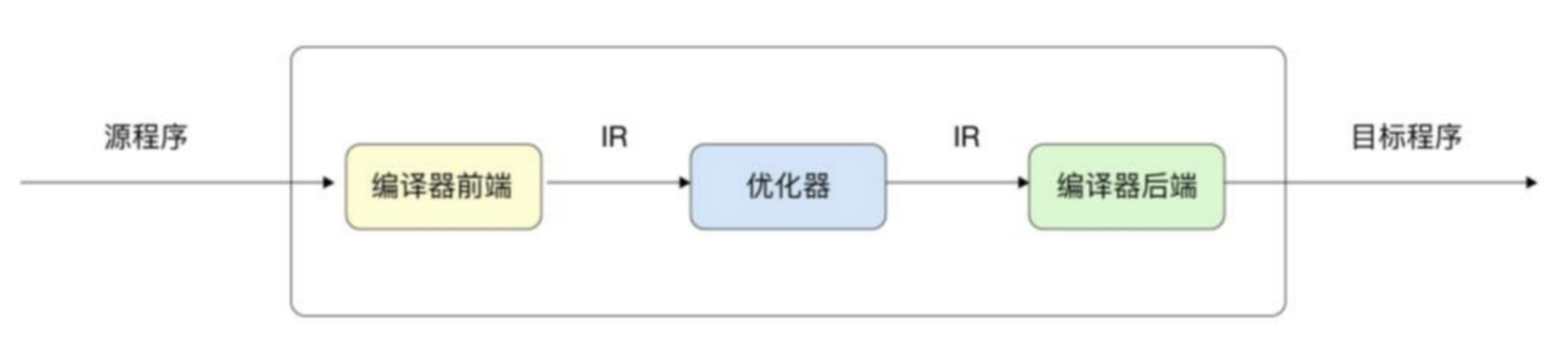
这种编译器被称为三阶段编译器(three-phase compiler)
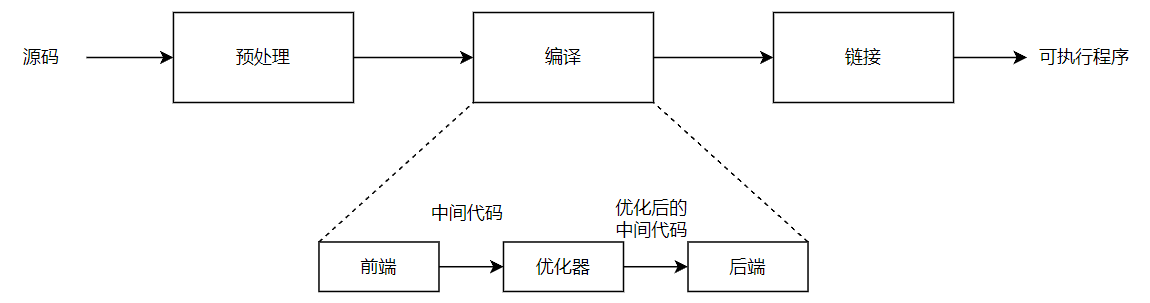
三个阶段的详细作用如下:
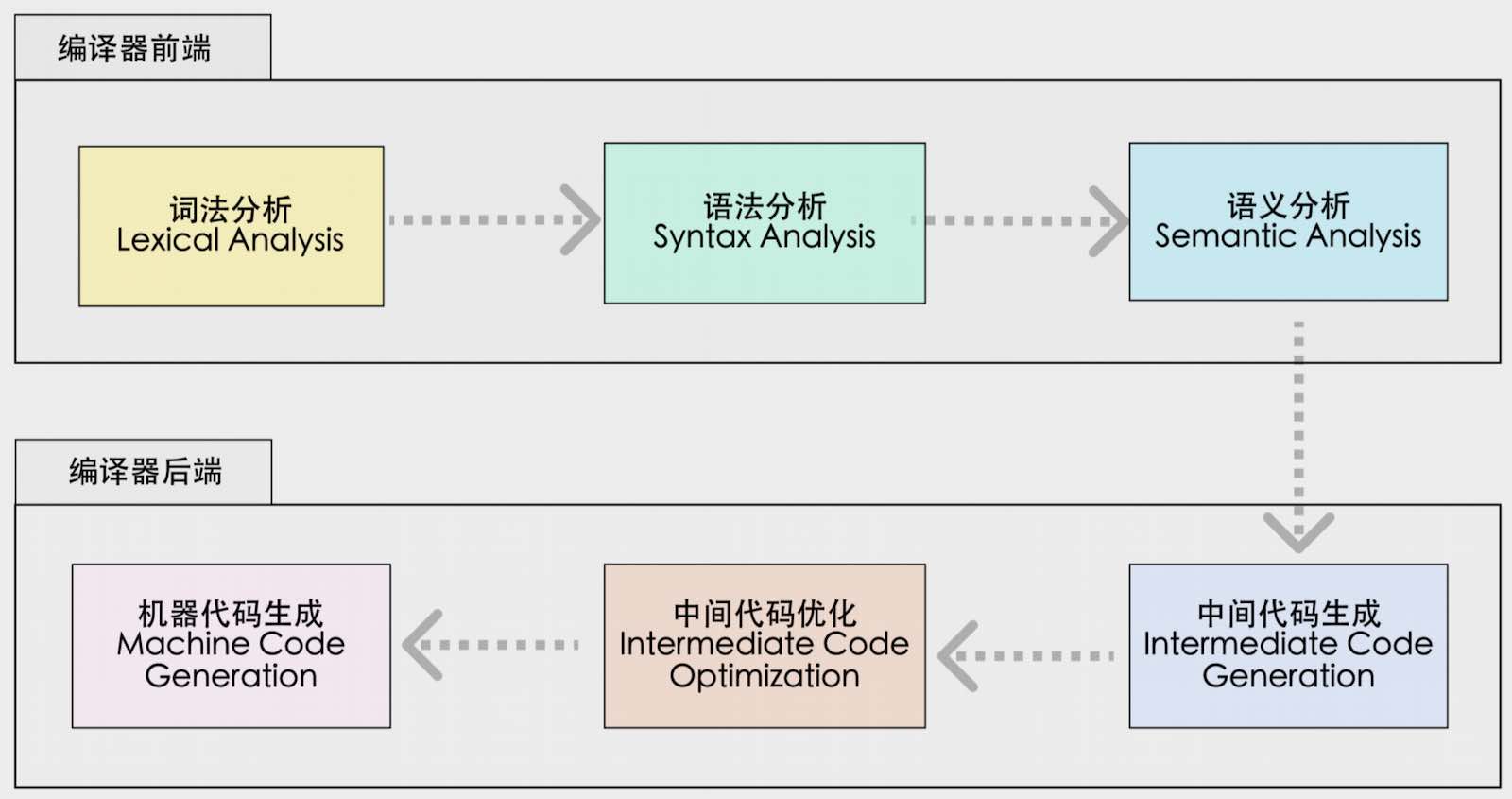
- 编译器前端
专注于理解源程序、扫描解析源程序并进行精准的语义表达
- 优化器(中间阶段)
编译器会使用多个 IR 阶段、多种数据结构表示代码,并在中间阶段对代码进行多次优化
例如:识别冗余代码、识别内存逃逸等
编译器的中间阶段离不开编译器前端记录的细节
- 编译器后端
专注于生成特定目标机器上的程序,这种程序可能是可执行文件,也可能是需要进一步处理的中间形态 obj 文件、汇编语言等
编译器优化并不是一个非常明确的概念
优化的主要目的一般是降低程序资源的消耗,比较常见的是降低内存与
CPU的使用率但在很多时候,这些目标可能是相互冲突的,对一个目标的优化可能降低另一个目标的效率
Go 编译器阶段
Go 语言编译器一般缩写为小写的 gc(go compiler),需要和大写的 GC(垃圾回收)进行区分
和 Go 语言编译器有关的代码主要位于 https://github.com/golang/go/tree/go1.20.1/src/cmd/compile
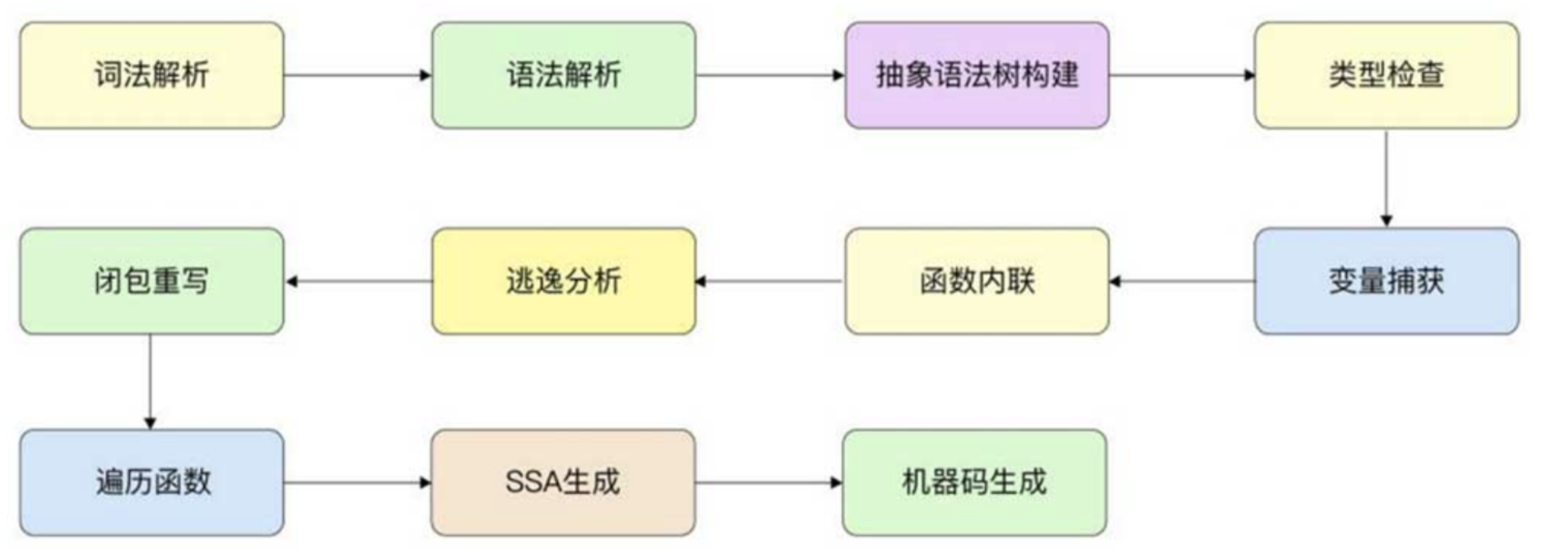
Go 的编译器在逻辑上可以被分成四个阶段:
- 词法与语法分析
- 类型检查和 AST 转换
- 通用 SSA 生成
- 机器代码生成
Go语言编译器的执行流程可细化为多个阶段,包括
-
词法与语法分析
-
词法解析 lexical analysis(lexer)
-
语法解析 syntax analysis
-
类型检查和 AST 转换
-
抽象语法树构建 syntax tree
-
类型检查 type checking
-
变量捕获 compiler types
-
函数内联 function call inlining
-
逃逸分析 escape analysis
-
闭包重写
-
遍历函数 devirtualization of known interface method calls
-
通用 SSA 生成
-
SSA 生成
-
机器代码生成
- 机器码生成 machine code generation
执行顺序如下图所示:
词法解析
在词法解析阶段,Go 语言编译器会扫描输入的 Go 源文件,并将其符号(token)化
例如将表达式 a := b + c(12) 符号化之后的情形,如下图所示:
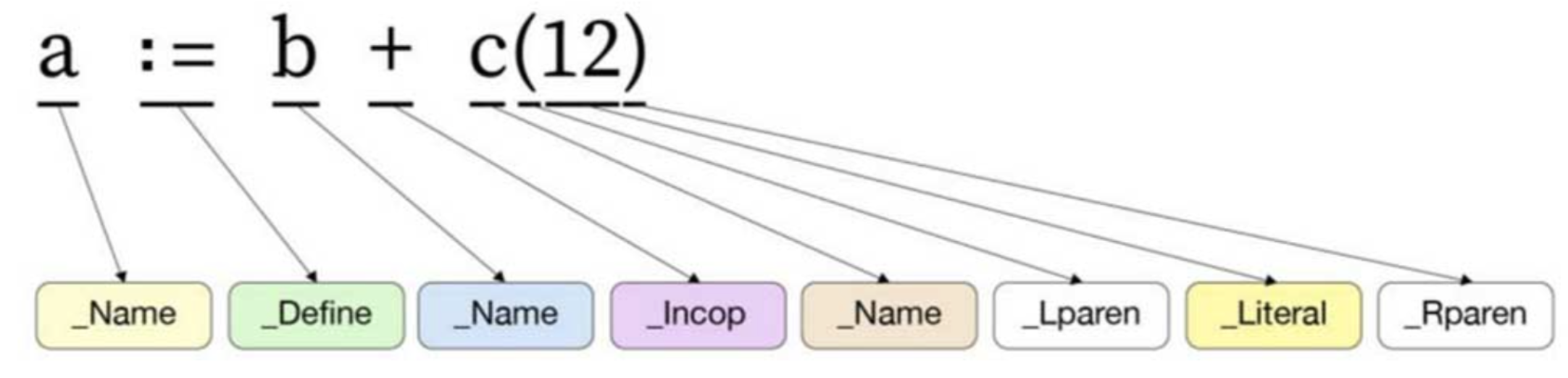
从上图可以看出:
+操作符会被转换为_IncOp;- 赋值符号
:=会被转换为_Define; - 变量名
a、b、c会被转换为_Name; - …
实际上,这些 token 就是用 iota 声明的整数常量,定义在 syntax/tokens.go 文件中
源码:https://github.com/golang/go/blob/go1.20.1/src/cmd/compile/internal/syntax/tokens.go#L7-L71
type token uint
//go:generate stringer -type token -linecomment tokens.go
const (
_ token = iota
_EOF // EOF
// names and literals
_Name // name
_Literal // literal
// operators and operations
// _Operator is excluding '*' (_Star)
_Operator // op
_AssignOp // op=
_IncOp // opop
_Assign // =
_Define // :=
_Arrow // <-
_Star // *
// delimiters
_Lparen // (
_Lbrack // [
_Lbrace // {
_Rparen // )
_Rbrack // ]
_Rbrace // }
_Comma // ,
_Semi // ;
_Colon // :
_Dot // .
_DotDotDot // ...
// keywords
_Break // break
_Case // case
_Chan // chan
_Const // const
_Continue // continue
_Default // default
_Defer // defer
_Else // else
_Fallthrough // fallthrough
_For // for
_Func // func
_Go // go
_Goto // goto
_If // if
_Import // import
_Interface // interface
_Map // map
_Package // package
_Range // range
_Return // return
_Select // select
_Struct // struct
_Switch // switch
_Type // type
_Var // var
// empty line comment to exclude it from .String
tokenCount //
)
- 符号化保留了
Go语言中定义的符号,可以识别出错误的拼写 - 字符串被转换为整数后,在后续的阶段中能够被更加高效地处理
语法解析
词法解析阶段结束后,需要根据 Go 语言中指定的语法对符号化后的 Go 文件进行解析
Go 语言采用了标准的自上而下的递归下降 [Top-Down Recursive-Descent] 算法,以简单高效的方式完成无须回溯的语法扫描
如下图示例:
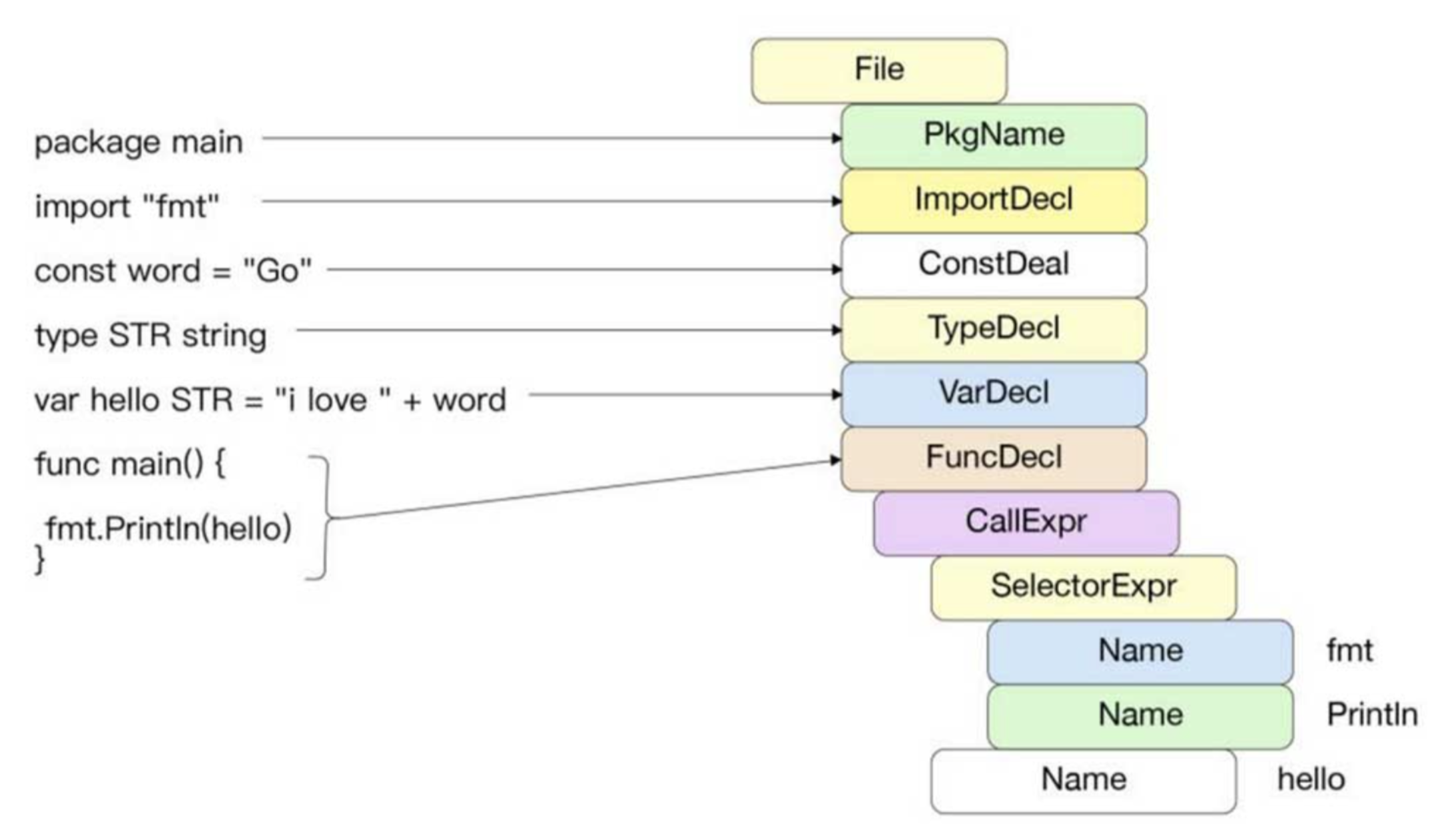
核心算法位于 syntax/nodes.go 及 syntax/parser.go 中
- https://github.com/golang/go/blob/go1.20.1/src/cmd/compile/internal/syntax/nodes.go
- https://github.com/golang/go/blob/go1.20.1/src/cmd/compile/internal/syntax/parser.go
源文件中的每一种声明都有对应的语法,采用对应的语法进行解析,能够较快地解析并识别可能出现的语法错误
抽象语法树构建
编译器前端必须构建程序的中间表示形式,以便在编译器中间阶段及后端使用,抽象语法树[Abstract Syntax Tree,AST]是一种常见的树状结构的中间态
在Go语言源文件中的任何一种 import、type、const、func 声明都是一个根节点,在根节点下包含当前声明的子节点
通过使用 decls 函数,将源文件中的所有声明语句转为节点数组。每个节点都包含了当前节点属性的 Op 字段,以 O 开头
-
与词法解析阶段中的
token相同的是,Op字段也是一个整数 -
不同的是,每个
Op字段都包含了语义信息,源码:https://github.com/golang/go/blob/go1.20.1/src/cmd/compile/internal/ir/node.go#L106-L314
//go:generate stringer -type=Op -trimprefix=O node.go
type Op uint8
// Node ops.
const (
OXXX Op = iota
// names
ONAME // var or func name
// Unnamed arg or return value: f(int, string) (int, error) { etc }
// Also used for a qualified package identifier that hasn't been resolved yet.
ONONAME
OTYPE // type name
OLITERAL // literal
ONIL // nil
// expressions
OADD // X + Y
OSUB // X - Y
OOR // X | Y
OXOR // X ^ Y
OADDSTR // +{List} (string addition, list elements are strings)
OADDR // &X
OANDAND // X && Y
OAPPEND // append(Args); after walk, X may contain elem type descriptor
OBYTES2STR // Type(X) (Type is string, X is a []byte)
OBYTES2STRTMP // Type(X) (Type is string, X is a []byte, ephemeral)
ORUNES2STR // Type(X) (Type is string, X is a []rune)
OSTR2BYTES // Type(X) (Type is []byte, X is a string)
OSTR2BYTESTMP // Type(X) (Type is []byte, X is a string, ephemeral)
OSTR2RUNES // Type(X) (Type is []rune, X is a string)
OSLICE2ARR // Type(X) (Type is [N]T, X is a []T)
OSLICE2ARRPTR // Type(X) (Type is *[N]T, X is a []T)
// X = Y or (if Def=true) X := Y
// If Def, then Init includes a DCL node for X.
OAS
// Lhs = Rhs (x, y, z = a, b, c) or (if Def=true) Lhs := Rhs
// If Def, then Init includes DCL nodes for Lhs
OAS2
OAS2DOTTYPE // Lhs = Rhs (x, ok = I.(int))
OAS2FUNC // Lhs = Rhs (x, y = f())
OAS2MAPR // Lhs = Rhs (x, ok = m["foo"])
OAS2RECV // Lhs = Rhs (x, ok = <-c)
OASOP // X AsOp= Y (x += y)
OCALL // X(Args) (function call, method call or type conversion)
// OCALLFUNC, OCALLMETH, and OCALLINTER have the same structure.
// Prior to walk, they are: X(Args), where Args is all regular arguments.
// After walk, if any argument whose evaluation might requires temporary variable,
// that temporary variable will be pushed to Init, Args will contains an updated
// set of arguments.
OCALLFUNC // X(Args) (function call f(args))
OCALLMETH // X(Args) (direct method call x.Method(args))
OCALLINTER // X(Args) (interface method call x.Method(args))
OCAP // cap(X)
OCLOSE // close(X)
OCLOSURE // func Type { Func.Closure.Body } (func literal)
OCOMPLIT // Type{List} (composite literal, not yet lowered to specific form)
OMAPLIT // Type{List} (composite literal, Type is map)
OSTRUCTLIT // Type{List} (composite literal, Type is struct)
OARRAYLIT // Type{List} (composite literal, Type is array)
OSLICELIT // Type{List} (composite literal, Type is slice), Len is slice length.
OPTRLIT // &X (X is composite literal)
OCONV // Type(X) (type conversion)
OCONVIFACE // Type(X) (type conversion, to interface)
OCONVIDATA // Builds a data word to store X in an interface. Equivalent to IDATA(CONVIFACE(X)). Is an ir.ConvExpr.
OCONVNOP // Type(X) (type conversion, no effect)
OCOPY // copy(X, Y)
ODCL // var X (declares X of type X.Type)
// Used during parsing but don't last.
ODCLFUNC // func f() or func (r) f()
ODCLCONST // const pi = 3.14
ODCLTYPE // type Int int or type Int = int
ODELETE // delete(Args)
ODOT // X.Sel (X is of struct type)
ODOTPTR // X.Sel (X is of pointer to struct type)
ODOTMETH // X.Sel (X is non-interface, Sel is method name)
ODOTINTER // X.Sel (X is interface, Sel is method name)
OXDOT // X.Sel (before rewrite to one of the preceding)
ODOTTYPE // X.Ntype or X.Type (.Ntype during parsing, .Type once resolved); after walk, Itab contains address of interface type descriptor and Itab.X contains address of concrete type descriptor
ODOTTYPE2 // X.Ntype or X.Type (.Ntype during parsing, .Type once resolved; on rhs of OAS2DOTTYPE); after walk, Itab contains address of interface type descriptor
OEQ // X == Y
ONE // X != Y
OLT // X < Y
OLE // X <= Y
OGE // X >= Y
OGT // X > Y
ODEREF // *X
OINDEX // X[Index] (index of array or slice)
OINDEXMAP // X[Index] (index of map)
OKEY // Key:Value (key:value in struct/array/map literal)
OSTRUCTKEY // Field:Value (key:value in struct literal, after type checking)
OLEN // len(X)
OMAKE // make(Args) (before type checking converts to one of the following)
OMAKECHAN // make(Type[, Len]) (type is chan)
OMAKEMAP // make(Type[, Len]) (type is map)
OMAKESLICE // make(Type[, Len[, Cap]]) (type is slice)
OMAKESLICECOPY // makeslicecopy(Type, Len, Cap) (type is slice; Len is length and Cap is the copied from slice)
// OMAKESLICECOPY is created by the order pass and corresponds to:
// s = make(Type, Len); copy(s, Cap)
//
// Bounded can be set on the node when Len == len(Cap) is known at compile time.
//
// This node is created so the walk pass can optimize this pattern which would
// otherwise be hard to detect after the order pass.
OMUL // X * Y
ODIV // X / Y
OMOD // X % Y
OLSH // X << Y
ORSH // X >> Y
OAND // X & Y
OANDNOT // X &^ Y
ONEW // new(X); corresponds to calls to new in source code
ONOT // !X
OBITNOT // ^X
OPLUS // +X
ONEG // -X
OOROR // X || Y
OPANIC // panic(X)
OPRINT // print(List)
OPRINTN // println(List)
OPAREN // (X)
OSEND // Chan <- Value
OSLICE // X[Low : High] (X is untypechecked or slice)
OSLICEARR // X[Low : High] (X is pointer to array)
OSLICESTR // X[Low : High] (X is string)
OSLICE3 // X[Low : High : Max] (X is untypedchecked or slice)
OSLICE3ARR // X[Low : High : Max] (X is pointer to array)
OSLICEHEADER // sliceheader{Ptr, Len, Cap} (Ptr is unsafe.Pointer, Len is length, Cap is capacity)
OSTRINGHEADER // stringheader{Ptr, Len} (Ptr is unsafe.Pointer, Len is length)
ORECOVER // recover()
ORECOVERFP // recover(Args) w/ explicit FP argument
ORECV // <-X
ORUNESTR // Type(X) (Type is string, X is rune)
OSELRECV2 // like OAS2: Lhs = Rhs where len(Lhs)=2, len(Rhs)=1, Rhs[0].Op = ORECV (appears as .Var of OCASE)
OREAL // real(X)
OIMAG // imag(X)
OCOMPLEX // complex(X, Y)
OALIGNOF // unsafe.Alignof(X)
OOFFSETOF // unsafe.Offsetof(X)
OSIZEOF // unsafe.Sizeof(X)
OUNSAFEADD // unsafe.Add(X, Y)
OUNSAFESLICE // unsafe.Slice(X, Y)
OUNSAFESLICEDATA // unsafe.SliceData(X)
OUNSAFESTRING // unsafe.String(X, Y)
OUNSAFESTRINGDATA // unsafe.StringData(X)
OMETHEXPR // X(Args) (method expression T.Method(args), first argument is the method receiver)
OMETHVALUE // X.Sel (method expression t.Method, not called)
// statements
OBLOCK // { List } (block of code)
OBREAK // break [Label]
// OCASE: case List: Body (List==nil means default)
// For OTYPESW, List is a OTYPE node for the specified type (or OLITERAL
// for nil) or an ODYNAMICTYPE indicating a runtime type for generics.
// If a type-switch variable is specified, Var is an
// ONAME for the version of the type-switch variable with the specified
// type.
OCASE
OCONTINUE // continue [Label]
ODEFER // defer Call
OFALL // fallthrough
OFOR // for Init; Cond; Post { Body }
OGOTO // goto Label
OIF // if Init; Cond { Then } else { Else }
OLABEL // Label:
OGO // go Call
ORANGE // for Key, Value = range X { Body }
ORETURN // return Results
OSELECT // select { Cases }
OSWITCH // switch Init; Expr { Cases }
// OTYPESW: X := Y.(type) (appears as .Tag of OSWITCH)
// X is nil if there is no type-switch variable
OTYPESW
OFUNCINST // instantiation of a generic function
// misc
// intermediate representation of an inlined call. Uses Init (assignments
// for the captured variables, parameters, retvars, & INLMARK op),
// Body (body of the inlined function), and ReturnVars (list of
// return values)
OINLCALL // intermediary representation of an inlined call.
OEFACE // itable and data words of an empty-interface value.
OITAB // itable word of an interface value.
OIDATA // data word of an interface value in X
OSPTR // base pointer of a slice or string.
OCFUNC // reference to c function pointer (not go func value)
OCHECKNIL // emit code to ensure pointer/interface not nil
ORESULT // result of a function call; Xoffset is stack offset
OINLMARK // start of an inlined body, with file/line of caller. Xoffset is an index into the inline tree.
OLINKSYMOFFSET // offset within a name
OJUMPTABLE // A jump table structure for implementing dense expression switches
// opcodes for generics
ODYNAMICDOTTYPE // x = i.(T) where T is a type parameter (or derived from a type parameter)
ODYNAMICDOTTYPE2 // x, ok = i.(T) where T is a type parameter (or derived from a type parameter)
ODYNAMICTYPE // a type node for type switches (represents a dynamic target type for a type switch)
// arch-specific opcodes
OTAILCALL // tail call to another function
OGETG // runtime.getg() (read g pointer)
OGETCALLERPC // runtime.getcallerpc() (continuation PC in caller frame)
OGETCALLERSP // runtime.getcallersp() (stack pointer in caller frame)
OEND
)
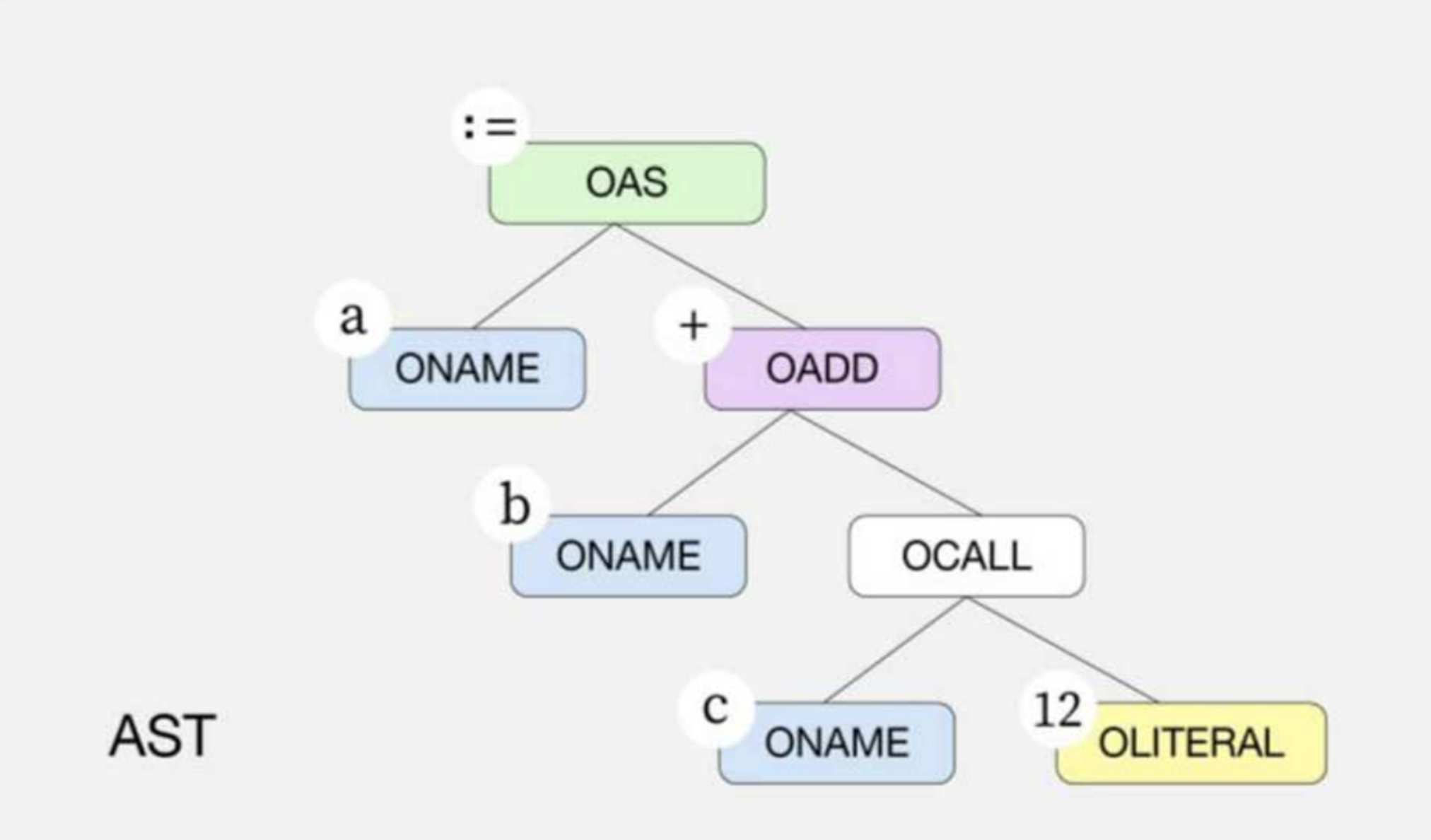
还是以 a := b + c(12)为例,该赋值语句最终会变为如下图所示的抽象语法树,节点之间具有从上到下的层次结构和依赖关系
类型检查
完成抽象语法树的初步构建后,就进入类型检查阶段,遍历节点树并决定节点的类型
节点的类型判断有以下两种情况:
- 明确指定的类型: 在语法中明确指定,例如
var a int - 需要通过编译器类型推断得到的类型: 例如,
a := 1中的变量a与常量1都未直接声明类型,编译器会自动推断出节点常量1的类型为TINT,并自动推断出a的类型为TINT
在类型检查阶段,会对一些类型做特别的语法或语义检查,例如:
- 引用的结构体字段是否是大写可导出的?
- 数组的访问是否超过了其长度?
- 数组的索引是不是正整数?
- ...
除此之外,在类型检查阶段还会进行其他工作。例如:
- 计算编译时常量
- 将标识符与声明绑定
- ...
源码位于:https://github.com/golang/go/tree/go1.20.1/src/cmd/compile/internal/types2
types2 包是 go/types 的端口,使用语法包的 AST 而不是 go/ast
变量捕获
类型检查阶段完成后,Go 语言编译器将对抽象语法树进行分析及重构,从而完成一系列优化
变量捕获主要是针对闭包场景而言的,由于闭包函数中可能引用闭包外的变量,因此变量捕获需要明确在闭包中通过值引用或地址引用的方式来捕获变量
package main
import "fmt"
func main() {
a := 1
b := 2
// 使用闭包
go func() {
fmt.Println(a, b)
}()
a = 99
}
上面例子中,在闭包内引入了闭包外的 a、b 变量,由于变量 a 在闭包之后又进行了其他赋值操作,因此在闭包中,a、b 变量的引用方式会有所不同
通过如下方式查看当前程序闭包变量捕获的情况:
执行下述命令:
遇到错误:
尚未解决
得到输出
# command-line-arguments
./main.go:5:6: cannot inline main: unhandled op GO
./main.go:9:5: can inline main.func1 with cost 78 as: func() { fmt.Println(a, b) }
./main.go:10:14: inlining call to fmt.Println
./main.go:9:5: func literal escapes to heap:
./main.go:9:5: flow: {heap} = &{storage for func literal}:
./main.go:9:5: from func literal (spill) at ./main.go:9:5
./main.go:6:2: main capturing by ref: a (addr=false assign=true width=8)
./main.go:6:2: a escapes to heap:
./main.go:6:2: flow: {storage for func literal} = &a:
./main.go:6:2: from a (captured by a closure) at ./main.go:10:15
./main.go:6:2: from a (reference) at ./main.go:10:15
./main.go:7:2: main capturing by value: b (addr=false assign=false width=8)
./main.go:10:18: b escapes to heap:
./main.go:10:18: flow: {storage for ... argument} = &{storage for b}:
./main.go:10:18: from b (spill) at ./main.go:10:18
./main.go:10:18: from ... argument (slice-literal-element) at ./main.go:10:14
./main.go:10:18: flow: fmt.a = &{storage for ... argument}:
./main.go:10:18: from ... argument (spill) at ./main.go:10:14
./main.go:10:18: from fmt.a := ... argument (assign-pair) at ./main.go:10:14
./main.go:10:18: flow: {heap} = *fmt.a:
./main.go:10:18: from fmt.Fprintln(os.Stdout, fmt.a...) (call parameter) at ./main.go:10:14
./main.go:10:15: a escapes to heap:
./main.go:10:15: flow: {storage for ... argument} = &{storage for a}:
./main.go:10:15: from a (spill) at ./main.go:10:15
./main.go:10:15: from ... argument (slice-literal-element) at ./main.go:10:14
./main.go:10:15: flow: fmt.a = &{storage for ... argument}:
./main.go:10:15: from ... argument (spill) at ./main.go:10:14
./main.go:10:15: from fmt.a := ... argument (assign-pair) at ./main.go:10:14
./main.go:10:15: flow: {heap} = *fmt.a:
./main.go:10:15: from fmt.Fprintln(os.Stdout, fmt.a...) (call parameter) at ./main.go:10:14
./main.go:6:2: moved to heap: a
./main.go:9:5: func literal escapes to heap
./main.go:10:14: ... argument does not escape
./main.go:10:15: a escapes to heap
./main.go:10:18: b escapes to heap
关注包含 capturing 的部分:
./main.go:6:2: main capturing by ref: a (addr=false assign=true width=8)
./main.go:7:2: main capturing by value: b (addr=false assign=false width=8)
上面输出说明:
by ref: a:a采取ref引用传递的方式by value: b:b采取了值传递的方式assign=true:代表变量a在闭包完成后又进行了赋值操作
函数内联
函数内联简介
函数内联指将较小的函数直接组合进调用者的函数
这是现代编译器优化的一种核心技术
优点
函数内联的优势在于,可以减少函数调用带来的开销
对于 Go 语言来说,函数调用的成本在于:
- 参数与返回值栈复制、较小的栈寄存器开销以及函数序言部分的检查栈扩容(
Go语言中的栈是可以动态扩容的)
性能对比
下面通过一段程序,来对比函数内联和不内联的性能
// tests/inline_bench_test.go
package tests
import "testing"
func max(a, b int) int {
if a > b {
return a
}
return b
}
// 使用了函数内联
func BenchmarkMax(b *testing.B) {
var a = 10
for i := 0; i < b.N; i++ {
// 进行大小计算
max(a, i)
}
}
//go:noinline
func maxNoInline(a, b int) int {
if a > b {
return a
}
return b
}
// 不使用函数内联
func BenchmarkNoInlineMax(b *testing.B) {
var a = 10
for i := 0; i < b.N; i++ {
// 进行大小计算
maxNoInline(a, i)
}
}
go:noinline:代表当前函数是禁止进行函数内联优化的
运行测试:
测试结果:
goos: linux
goarch: amd64
cpu: AMD Ryzen 9 5950X 16-Core Processor
BenchmarkMax-32 1000000000 0.2159 ns/op
BenchmarkNoInlineMax-32 789073452 1.547 ns/op
PASS
ok command-line-arguments 1.616s
不使用内联
如何不使用内联
Go 语言编译器会计算函数内联花费的成本,只有执行相对简单的函数时才会内联
函数内联的核心逻辑位于 inline/inl.go 中,源码:https://github.com/golang/go/blob/go1.20.1/src/cmd/compile/internal/inline/inl.go
以下情况都不会使用函数内联: - 当函数内部有 for、range、go、select 等语句时,该函数不会被内联 - 当函数执行过于复杂(例如太多的语句或者函数为递归函数)时,也不会执行内联 - 如果函数前的注释中有 go:noinline 标识,则该函数不会执行内联
源码位于:https://github.com/golang/go/blob/go1.20.1/src/cmd/compile/internal/inline/inl.go#L215-L360
// CanInline determines whether fn is inlineable.
// If so, CanInline saves copies of fn.Body and fn.Dcl in fn.Inl.
// fn and fn.Body will already have been typechecked.
func CanInline(fn *ir.Func, profile *pgo.Profile) {
if fn.Nname == nil {
base.Fatalf("CanInline no nname %+v", fn)
}
var reason string // reason, if any, that the function was not inlined
if base.Flag.LowerM > 1 || logopt.Enabled() {
defer func() {
if reason != "" {
if base.Flag.LowerM > 1 {
fmt.Printf("%v: cannot inline %v: %s\n", ir.Line(fn), fn.Nname, reason)
}
if logopt.Enabled() {
logopt.LogOpt(fn.Pos(), "cannotInlineFunction", "inline", ir.FuncName(fn), reason)
}
}
}()
}
// If marked "go:noinline", don't inline
if fn.Pragma&ir.Noinline != 0 {
reason = "marked go:noinline"
return
}
// If marked "go:norace" and -race compilation, don't inline.
if base.Flag.Race && fn.Pragma&ir.Norace != 0 {
reason = "marked go:norace with -race compilation"
return
}
// If marked "go:nocheckptr" and -d checkptr compilation, don't inline.
if base.Debug.Checkptr != 0 && fn.Pragma&ir.NoCheckPtr != 0 {
reason = "marked go:nocheckptr"
return
}
// If marked "go:cgo_unsafe_args", don't inline, since the
// function makes assumptions about its argument frame layout.
if fn.Pragma&ir.CgoUnsafeArgs != 0 {
reason = "marked go:cgo_unsafe_args"
return
}
// If marked as "go:uintptrkeepalive", don't inline, since the
// keep alive information is lost during inlining.
//
// TODO(prattmic): This is handled on calls during escape analysis,
// which is after inlining. Move prior to inlining so the keep-alive is
// maintained after inlining.
if fn.Pragma&ir.UintptrKeepAlive != 0 {
reason = "marked as having a keep-alive uintptr argument"
return
}
// If marked as "go:uintptrescapes", don't inline, since the
// escape information is lost during inlining.
if fn.Pragma&ir.UintptrEscapes != 0 {
reason = "marked as having an escaping uintptr argument"
return
}
// The nowritebarrierrec checker currently works at function
// granularity, so inlining yeswritebarrierrec functions can
// confuse it (#22342). As a workaround, disallow inlining
// them for now.
if fn.Pragma&ir.Yeswritebarrierrec != 0 {
reason = "marked go:yeswritebarrierrec"
return
}
// If fn has no body (is defined outside of Go), cannot inline it.
if len(fn.Body) == 0 {
reason = "no function body"
return
}
if fn.Typecheck() == 0 {
base.Fatalf("CanInline on non-typechecked function %v", fn)
}
n := fn.Nname
if n.Func.InlinabilityChecked() {
return
}
defer n.Func.SetInlinabilityChecked(true)
cc := int32(inlineExtraCallCost)
if base.Flag.LowerL == 4 {
cc = 1 // this appears to yield better performance than 0.
}
// Update the budget for profile-guided inlining.
budget := int32(inlineMaxBudget)
if profile != nil {
if n, ok := profile.WeightedCG.IRNodes[ir.PkgFuncName(fn)]; ok {
if _, ok := candHotCalleeMap[n]; ok {
budget = int32(inlineHotMaxBudget)
if base.Debug.PGOInline > 0 {
fmt.Printf("hot-node enabled increased budget=%v for func=%v\n", budget, ir.PkgFuncName(fn))
}
}
}
}
// At this point in the game the function we're looking at may
// have "stale" autos, vars that still appear in the Dcl list, but
// which no longer have any uses in the function body (due to
// elimination by deadcode). We'd like to exclude these dead vars
// when creating the "Inline.Dcl" field below; to accomplish this,
// the hairyVisitor below builds up a map of used/referenced
// locals, and we use this map to produce a pruned Inline.Dcl
// list. See issue 25249 for more context.
visitor := hairyVisitor{
curFunc: fn,
budget: budget,
maxBudget: budget,
extraCallCost: cc,
profile: profile,
}
if visitor.tooHairy(fn) {
reason = visitor.reason
return
}
n.Func.Inl = &ir.Inline{
Cost: budget - visitor.budget,
Dcl: pruneUnusedAutos(n.Defn.(*ir.Func).Dcl, &visitor),
Body: inlcopylist(fn.Body),
CanDelayResults: canDelayResults(fn),
}
if base.Flag.LowerM > 1 {
fmt.Printf("%v: can inline %v with cost %d as: %v { %v }\n", ir.Line(fn), n, budget-visitor.budget, fn.Type(), ir.Nodes(n.Func.Inl.Body))
} else if base.Flag.LowerM != 0 {
fmt.Printf("%v: can inline %v\n", ir.Line(fn), n)
}
if logopt.Enabled() {
logopt.LogOpt(fn.Pos(), "canInlineFunction", "inline", ir.FuncName(fn), fmt.Sprintf("cost: %d", budget-visitor.budget))
}
}
如果希望程序中所有的函数都不执行内联操作,那么可以添加编译器选项 -l
调试不使用内联的原因
在调试时,可以使用 go tool compile -m=2 来打印调试信息,并输出不可以内联的原因,如下代码:
package main
// 使用递归
func fib(i int) int {
if i < 2 {
return i
}
return fib(i-1) + fib(i-2)
}
func main() {
i := 10
fib(i)
}
当在编译时加入-m=2标志时,可以打印出函数的内联调试信息
可以看出 fib函数为递归函数,所以不能被内联
# command-line-arguments
./main.go:4:6: cannot inline fib: recursive
./main.go:11:6: can inline main with cost 65 as: func() { i := 10; fib(i) }
逃逸分析
逃逸分析简介
逃逸分析是 Go 语言中重要的优化阶段,用于标识变量内存应该被分配在栈区还是堆区。
在传统的 C 或 C++ 语言中,开发者经常会犯的错误是函数返回了一个栈上的对象指针,在函数执行完成,栈被销毁后,继续访问被销毁栈上的对象指针,导致出现问题。
Go 语言能够通过编译时的逃逸分析识别这种问题:
- 自动将该变量放置到堆区,并借助
Go运行时的垃圾回收机制自动释放内存 - 编译器会尽可能地将变量放置到栈中,因为栈中的对象随着函数调用结束会被自动销毁,减轻运行时分配和垃圾回收的负担
分配原则
在 Go 语言中,开发者模糊了栈区与堆区的差别,不管是字符串、数组字面量,还是通过 new、make 标识符创建的对象,都既可能被分配到栈中,也可能被分配到堆中
分配时,遵循以下两个原则:
- 原则 1:指向栈上对象的指针不能被存储到堆中
- 原则 2:指向栈上对象的指针不能超过该栈对象的生命周期
例如:
运行测试:
得到输出:
# command-line-arguments
./main.go:6:6: can inline main with cost 9 as: func() { b := 1; a = &b }
./main.go:8:2: b escapes to heap:
./main.go:8:2: flow: {heap} = &b:
./main.go:8:2: from &b (address-of) at ./main.go:10:6
./main.go:8:2: from a = &b (assign) at ./main.go:10:4
./main.go:8:2: moved to heap: b
在上例中:
- 变量
a为全局变量,是一个指针 - 在函数中,全局变量
a引用了局部变量b的地址 - 如果变量
b被分配到栈中,那么最终程序将违背原则 2,因此变量b最终将被分配到堆中
闭包重写
在前面的阶段,编译器完成了闭包变量的捕获用于决定是通过指针引用还是值引用的方式传递外部变量
在完成逃逸分析后,下一个优化的阶段为闭包重写
闭包重写分为以下两种情况:
- 闭包定义后被立即调用: 这种情况下,闭包只能被调用一次,可以将闭包转换为普通函数的调用形式
- 包定义后不被立即调用: 同一个闭包可能被调用多次,这时需要创建闭包对象
闭包重写示例
下面示例展示的是闭包函数,重写后的样子
package main
import "fmt"
// 闭包定义后被立即调用
func todo() {
a := 1
func() {
fmt.Println(a)
a = 2
}()
}
func main() {
todo()
}
闭包重写后:
package main
import "fmt"
func todo() {
a := 1
func1(&a)
fmt.Println("aa:", a)
}
func func1(a *int) {
fmt.Println(*a)
*a = 2
}
func main() {
todo()
}
遍历函数
闭包重写后,需要遍历函数
在该阶段会识别出声明但是并未被使用的变量,遍历函数中的声明和表达式,将某些代表操作的节点转换为运行时的具体函数执行
例如,获取 map 中的值
会被转换为运行时 mapaccess2_fast64 函数,源码见:https://github.com/golang/go/blob/go1.20.1/src/runtime/map_fast64.go#L53-L91
其他情形:
- 字符串变量的拼接会被转换为调用运行时
concatstrings函数 - 对于
new操作,如果变量发生了逃逸,那么最终会调用运行时newobject函数将变量分配到堆区 for...range语句会重写为更简单的for语句形式
SSA 生成
SSA 简介
遍历函数后,编译器会将抽象语法树转换为下一个重要的中间表示形态,称为 SSA(Static Single Assignment,静态单赋值)
SSA 被大多数现代的编译器(包括 GCC 和 LLVM)使用,在 Go 1.7 中被正式引入并替换了之前的编译器后端,用于最终生成更有效的机器码
在 SSA 生成阶段,每个变量在声明之前都需要被定义,并且,每个变量只会被赋值一次
SSA阶段作用
SSA 生成阶段是编译器进行后续优化的保证,例如
- 常量传播(Constant Propagation)
- 无效代码清除
- 消除冗余
- 强度降低(Strength Reduction)
- ...
在 SSA 阶段,编译器先执行与特定指令集无关的优化,再执行与特定指令集有关的优化,并最终生成与特定指令集有关的指令和寄存器分配方式
SSA lower阶段之后:开始执行与特定指令集有关的重写与优化genssa阶段:编译器会生成与单个指令对应的Prog结构
生成 SSA
Go 语言提供了强有力的工具查看 SSA 初始及其后续优化阶段生成的代码片段
可以通过在编译时指定 GOSSAFUNC=main 实现
例如
会输出文件到 ssa.html
# runtime
dumped SSA to /code/code.liaosirui.com/z-demo/go-demo/ssa.html
# command-line-arguments
dumped SSA to ./ssa.html
点击左侧的源码,会自动标亮对应代码生成的信息
展示了 SSA 的初始阶段、优化阶段、最终阶段 的代码片段

机器码生成
机器码生成阶段
在 SSA 后,编译器将调用与特定指令集有关的 汇编器(Assembler) 生成 obj 文件,obj 文件作为 链接器(Linker) 的输入,生成二进制可执行文件
汇编和链接是编译器后端与特定指令集有关的阶段。由于历史原因,Go 语言的汇编器基于了不太常见的 plan9 汇编器的输入形式。需要注意的是,输入汇编器中的汇编指令不是机器码的表现形式,其仍然是人类可读的底层抽象。
源程序转汇编代码
源程序:
转成汇编代码:
得到输出
# command-line-arguments
main.main STEXT size=103 args=0x0 locals=0x40 funcid=0x0 align=0x0
0x0000 00000 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) TEXT main.main(SB), ABIInternal, $64-0
0x0000 00000 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) CMPQ SP, 16(R14)
0x0004 00004 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) PCDATA $0, $-2
0x0004 00004 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) JLS 92
0x0006 00006 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) PCDATA $0, $-1
0x0006 00006 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) SUBQ $64, SP
0x000a 00010 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) MOVQ BP, 56(SP)
0x000f 00015 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) LEAQ 56(SP), BP
0x0014 00020 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) FUNCDATA $0, gclocals·g2BeySu+wFnoycgXfElmcg==(SB)
0x0014 00020 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) FUNCDATA $1, gclocals·EaPwxsZ75yY1hHMVZLmk6g==(SB)
0x0014 00020 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) FUNCDATA $2, main.main.stkobj(SB)
0x0014 00020 (/code/code.liaosirui.com/z-demo/go-demo/main.go:6) MOVUPS X15, main..autotmp_8+40(SP)
0x001a 00026 (/code/code.liaosirui.com/z-demo/go-demo/main.go:6) LEAQ type:string(SB), DX
0x0021 00033 (/code/code.liaosirui.com/z-demo/go-demo/main.go:6) MOVQ DX, main..autotmp_8+40(SP)
0x0026 00038 (/code/code.liaosirui.com/z-demo/go-demo/main.go:6) LEAQ main..stmp_0(SB), DX
0x002d 00045 (/code/code.liaosirui.com/z-demo/go-demo/main.go:6) MOVQ DX, main..autotmp_8+48(SP)
0x0032 00050 (<unknown line number>) NOP
0x0032 00050 (/root/.g/go/src/fmt/print.go:314) MOVQ os.Stdout(SB), BX
0x0039 00057 (/root/.g/go/src/fmt/print.go:314) LEAQ go:itab.*os.File,io.Writer(SB), AX
0x0040 00064 (/root/.g/go/src/fmt/print.go:314) LEAQ main..autotmp_8+40(SP), CX
0x0045 00069 (/root/.g/go/src/fmt/print.go:314) MOVL $1, DI
0x004a 00074 (/root/.g/go/src/fmt/print.go:314) MOVQ DI, SI
0x004d 00077 (/root/.g/go/src/fmt/print.go:314) PCDATA $1, $0
0x004d 00077 (/root/.g/go/src/fmt/print.go:314) CALL fmt.Fprintln(SB)
0x0052 00082 (/code/code.liaosirui.com/z-demo/go-demo/main.go:7) MOVQ 56(SP), BP
0x0057 00087 (/code/code.liaosirui.com/z-demo/go-demo/main.go:7) ADDQ $64, SP
0x005b 00091 (/code/code.liaosirui.com/z-demo/go-demo/main.go:7) RET
0x005c 00092 (/code/code.liaosirui.com/z-demo/go-demo/main.go:7) NOP
0x005c 00092 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) PCDATA $1, $-1
0x005c 00092 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) PCDATA $0, $-2
0x005c 00092 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) NOP
0x0060 00096 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) CALL runtime.morestack_noctxt(SB)
0x0065 00101 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) PCDATA $0, $-1
0x0065 00101 (/code/code.liaosirui.com/z-demo/go-demo/main.go:5) JMP 0
0x0000 49 3b 66 10 76 56 48 83 ec 40 48 89 6c 24 38 48 I;f.vVH..@H.l$8H
0x0010 8d 6c 24 38 44 0f 11 7c 24 28 48 8d 15 00 00 00 .l$8D..|$(H.....
0x0020 00 48 89 54 24 28 48 8d 15 00 00 00 00 48 89 54 .H.T$(H......H.T
0x0030 24 30 48 8b 1d 00 00 00 00 48 8d 05 00 00 00 00 $0H......H......
0x0040 48 8d 4c 24 28 bf 01 00 00 00 48 89 fe e8 00 00 H.L$(.....H.....
0x0050 00 00 48 8b 6c 24 38 48 83 c4 40 c3 0f 1f 40 00 ..H.l$8H..@...@.
0x0060 e8 00 00 00 00 eb 99 .......
rel 2+0 t=23 type:string+0
rel 2+0 t=23 type:*os.File+0
rel 29+4 t=14 type:string+0
rel 41+4 t=14 main..stmp_0+0
rel 53+4 t=14 os.Stdout+0
rel 60+4 t=14 go:itab.*os.File,io.Writer+0
rel 78+4 t=7 fmt.Fprintln+0
rel 97+4 t=7 runtime.morestack_noctxt+0
go:cuinfo.producer.main SDWARFCUINFO dupok size=0
0x0000 72 65 67 61 62 69 regabi
go:cuinfo.packagename.main SDWARFCUINFO dupok size=0
0x0000 6d 61 69 6e main
go:info.fmt.Println$abstract SDWARFABSFCN dupok size=42
0x0000 05 66 6d 74 2e 50 72 69 6e 74 6c 6e 00 01 01 13 .fmt.Println....
0x0010 61 00 00 00 00 00 00 13 6e 00 01 00 00 00 00 13 a.......n.......
0x0020 65 72 72 00 01 00 00 00 00 00 err.......
rel 0+0 t=22 type:[]interface {}+0
rel 0+0 t=22 type:error+0
rel 0+0 t=22 type:int+0
rel 19+4 t=31 go:info.[]interface {}+0
rel 27+4 t=31 go:info.int+0
rel 37+4 t=31 go:info.error+0
go:itab.*os.File,io.Writer SRODATA dupok size=32
0x0000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0x0010 5a 22 ee 60 00 00 00 00 00 00 00 00 00 00 00 00 Z".`............
rel 0+8 t=1 type:io.Writer+0
rel 8+8 t=1 type:*os.File+0
rel 24+8 t=-32767 os.(*File).Write+0
main..inittask SNOPTRDATA size=32
0x0000 00 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00 ................
0x0010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
rel 24+8 t=1 fmt..inittask+0
go:string."hello word" SRODATA dupok size=10
0x0000 68 65 6c 6c 6f 20 77 6f 72 64 hello word
main..stmp_0 SRODATA static size=16
0x0000 00 00 00 00 00 00 00 00 0a 00 00 00 00 00 00 00 ................
rel 0+8 t=1 go:string."hello word"+0
runtime.nilinterequal·f SRODATA dupok size=8
0x0000 00 00 00 00 00 00 00 00 ........
rel 0+8 t=1 runtime.nilinterequal+0
runtime.memequal64·f SRODATA dupok size=8
0x0000 00 00 00 00 00 00 00 00 ........
rel 0+8 t=1 runtime.memequal64+0
runtime.gcbits.0100000000000000 SRODATA dupok size=8
0x0000 01 00 00 00 00 00 00 00 ........
type:.namedata.*[1]interface {}- SRODATA dupok size=18
0x0000 00 10 2a 5b 31 5d 69 6e 74 65 72 66 61 63 65 20 ..*[1]interface
0x0010 7b 7d {}
type:*[1]interface {} SRODATA dupok size=56
0x0000 08 00 00 00 00 00 00 00 08 00 00 00 00 00 00 00 ................
0x0010 a8 0e 57 36 08 08 08 36 00 00 00 00 00 00 00 00 ..W6...6........
0x0020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0x0030 00 00 00 00 00 00 00 00 ........
rel 24+8 t=1 runtime.memequal64·f+0
rel 32+8 t=1 runtime.gcbits.0100000000000000+0
rel 40+4 t=5 type:.namedata.*[1]interface {}-+0
rel 48+8 t=1 type:[1]interface {}+0
runtime.gcbits.0200000000000000 SRODATA dupok size=8
0x0000 02 00 00 00 00 00 00 00 ........
type:[1]interface {} SRODATA dupok size=72
0x0000 10 00 00 00 00 00 00 00 10 00 00 00 00 00 00 00 ................
0x0010 6e 20 6a 3d 02 08 08 11 00 00 00 00 00 00 00 00 n j=............
0x0020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0x0030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0x0040 01 00 00 00 00 00 00 00 ........
rel 24+8 t=1 runtime.nilinterequal·f+0
rel 32+8 t=1 runtime.gcbits.0200000000000000+0
rel 40+4 t=5 type:.namedata.*[1]interface {}-+0
rel 44+4 t=-32763 type:*[1]interface {}+0
rel 48+8 t=1 type:interface {}+0
rel 56+8 t=1 type:[]interface {}+0
type:.importpath.fmt. SRODATA dupok size=5
0x0000 00 03 66 6d 74 ..fmt
gclocals·g2BeySu+wFnoycgXfElmcg== SRODATA dupok size=8
0x0000 01 00 00 00 00 00 00 00 ........
gclocals·EaPwxsZ75yY1hHMVZLmk6g== SRODATA dupok size=9
0x0000 01 00 00 00 02 00 00 00 00 .........
main.main.stkobj SRODATA static size=24
0x0000 01 00 00 00 00 00 00 00 f0 ff ff ff 10 00 00 00 ................
0x0010 10 00 00 00 00 00 00 00 ........
rel 20+4 t=5 runtime.gcbits.0200000000000000+0