通道Channel
Channel 简介
Go 核心的数据结构和 Goroutine 之间的通信方式,Channel 是支撑 Go 语言高性能并发编程模型的重要结构
语法和使用示例
通道的特性
Go语言中的通道(channel)是一种特殊的类型
在任何时候,同时只能有一个 goroutine 访问通道进行发送和获取数据
goroutine 间通过通道就可以通信
通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序
声明通道类型
通道本身需要一个类型进行修饰,就像切片类型需要标识元素类型。通道的元素类型就是在其内部传输的数据类型,声明如下:
- 通道类型:通道内的数据类型
- 通道变量:保存通道的变量
chan 类型的空值是 nil,声明后需要配合 make 后才能使用
创建通道
通道是引用类型,需要使用 make 进行创建,格式如下:
- 数据类型:通道内传输的元素类型
- 通道实例:通过make创建的通道句柄
例子:
ch1 := make(chan int) // 创建一个整型类型的通道
ch2 := make(chan interface{}) // 创建一个空接口类型的通道, 可以存放任意格式
type Equip struct{ /* 一些字段 */ }
ch2 := make(chan *Equip) // 创建 Equip 指针类型的通道, 可以存放 *Equip
完整的例子:
package main
import "fmt"
func main() {
// 1. 声明一个管道
var mych chan int
// 2. 初始化一个管道
mych = make(chan int, 3)
// 3. 查看管道的长度和容量
fmt.Println("长度是", len(mych), "容量是", cap(mych))
// 4. 向管道中写入数据
mych <- 666
fmt.Println("长度是", len(mych), "容量是", cap(mych))
// 5. 取出管道中写入的数据
num := <-mych
fmt.Println("num = ", num)
fmt.Println("长度是", len(mych), "容量是", cap(mych))
}
// 输出:
// 长度是 0 容量是 3
// 长度是 1 容量是 3
// num = 666
// 长度是 0 容量是 3
使用通道发送数据
通道创建后,就可以使用通道进行发送和接收操作
(1)通道发送数据的格式
通道的发送使用特殊的操作符 <-,将数据通过通道发送的格式为:
- 通道变量:通过 make 创建好的通道实例
- 值:可以是变量、常量、表达式或者函数返回值等;值的类型必须与 ch 通道的元素类型一致
(2)通过通道发送数据的例子
使用 make 创建一个通道后,就可以使用 <- 向通道发送数据,代码如下:
(3)发送将持续阻塞直到数据被接收
把数据往通道中发送时,如果接收方一直都没有接收,那么发送操作将持续阻塞
Go 程序运行时能智能地发现一些永远无法发送成功的语句并做出提示,代码如下:
运行代码,报错:
报错的意思是:运行时发现所有的 goroutine(包括 main)都处于等待 goroutine
也就是说所有 goroutine 中的 channel 并没有形成发送和接收对应的代码
使用通道接收数据
通道接收同样使用 <- 操作符,通道接收有如下特性:
- 通道的收发操作在不同的两个 goroutine 间进行
由于通道的数据在没有接收方处理时,数据发送方会持续阻塞,因此通道的接收必定在另外一个 goroutine 中进行
- 接收将持续阻塞直到发送方发送数据
如果接收方接收时,通道中没有发送方发送数据,接收方也会发生阻塞,直到发送方发送数据为止
- 每次接收一个元素
通道一次只能接收一个数据元素
通道的数据接收一共有以下 4 种写法:
(1)阻塞接收数据
阻塞模式接收数据时,将接收变量作为 <- 操作符的左值,格式如下:
执行该语句时将会阻塞,直到接收到数据并赋值给 data 变量
(2)非阻塞接收数据
使用非阻塞方式从通道接收数据时,语句不会发生阻塞,格式如下:
-
data:表示接收到的数据;未接收到数据时,data 为通道类型的零值
-
ok:表示是否接收到数据
非阻塞的通道接收方法可能造成高的 CPU 占用,因此使用非常少
如果需要实现接收超时检测,可以配合 select 和计时器 channel 进行
(3)接收任意数据,忽略接收的数据
阻塞接收数据后,忽略从通道返回的数据,格式如下:
执行该语句时将会发生阻塞,直到接收到数据,但接收到的数据会被忽略
这个方式实际上只是通过通道在 goroutine 间阻塞收发实现并发同步
使用通道做并发同步的写法,可以参考下面的例子:
package main
import (
"fmt"
)
func main() {
// 构建一个同步用的通道
ch := make(chan int)
// 开启一个并发匿名函数
go func() {
fmt.Println("start goroutine")
// 通过通道通知 main 的 goroutine
ch <- 0
fmt.Println("exit goroutine")
}()
fmt.Println("wait goroutine")
// 等待匿名 goroutine
<-ch
fmt.Println("all done")
}
(4)循环接收
通道的数据接收可以借用 for range 语句进行多个元素的接收操作,格式如下:
通道 ch 是可以进行遍历的,遍历的结果就是接收到的数据
数据类型就是通道的数据类型
通过 for 遍历获得的变量只有一个,即上面例子中的 data
使用 for 从通道中接收数据:
package main
import (
"fmt"
"time"
)
func main() {
// 构建一个通道
ch := make(chan int)
// 开启一个并发匿名函数
go func() {
// 从 3 循环到 0
for i := 3; i >= 0; i-- {
// 发送 3 到 0 之间的数值
ch <- i
// 每次发送完时等待
time.Sleep(time.Second)
}
}()
// 遍历接收通道数据
for data := range ch {
// 打印通道数据
fmt.Println(data)
// 当遇到数据 0 时, 退出接收循环
if data == 0 {
break
}
}
}
单向和双向通道
- 双向管道 bi-directional channel
- 单向管道 uni-directional channel
// send-only channel
var sendOnlyCh chan<- int = make(chan<- int, 0)
// receive-only channel
var readOnlyCh <-chan int = make(<-chan int, 0)
默认情况下所有管道都是双向(可读可写)
注意点:
-
双向管道可以自动转换为任意一种单向管道
-
单向管道不能转换为双向管道
单向 channel 的一个典型使用场景是作为函数或方法参数,用来控制只能往 channel 发送数据或者只能从 channel 接收数据,避免误操作
package main
import (
"fmt"
)
// send-only channel
func testSendChan(c chan<- int) {
c <- 20
}
// receive-only channel
func testRecvChan(c <-chan int) {
result := <-c
fmt.Println("result:", result)
}
func main() {
ch := make(chan int, 3)
testSendChan(ch)
testRecvChan(ch)
}
带缓存和不带缓存通道
同一个协程里,不能对无缓冲 channel 同时发送和接收数据,如果这么做会直接报错死锁
对于一个无缓冲的 channel 而言,只有不同的协程之间一方发送数据一方接受数据才不会阻塞;channel无缓冲时,发送阻塞直到数据被接收,接收阻塞直到读到数据
应用场景
(1)任务定时
比如超时处理:
定时任务:
(2)解耦生产者和消费者
可以将生产者和消费者解耦出来,生产者只需要往 channel 发送数据,而消费者只管从 channel 中获取数据
(3)控制并发数量
以爬虫为例,比如需要爬取 1w 条数据,需要并发爬取以提高效率,但并发量又不能过大,可以通过 channel 来控制并发规模,比如同时支持 5 个并发任务:
使用示例
循环交替打印
package main
import (
"fmt"
"sync"
)
const CountSize = 5
func main() {
wg := sync.WaitGroup{}
chanA := make(chan struct{}, 1)
chanB := make(chan struct{}, 1)
chanC := make(chan struct{}, 1)
chanA <- struct{}{}
wg.Add(3)
go print(&wg, chanA, chanB, "A")
go print(&wg, chanB, chanC, "B")
go print(&wg, chanC, chanA, "C")
wg.Wait()
}
func print(wg *sync.WaitGroup, chanX, chanY chan struct{}, message string) {
defer wg.Done()
for i := 0; i < CountSize; i++ {
<-chanX
fmt.Println(message)
chanY <- struct{}{}
}
}
使用 channel 控制并发数量
goroutine 是轻量级线程,调度由 Go 运行时进行管理的
Go 语言的并发控制主要使用关键字 go 开启协程 goroutine
Go 协程(Goroutine)之间通过信道(channel)进行通信,简单的说就是多个协程之间通信的管道
信道可以防止多个协程访问共享内存时发生资源争抢的问题
语法格式:
协程可以开启多少个?是否有限制呢?
package main
import (
"fmt"
"math"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
for i := 0; i < math.MaxInt32; i++ {
wg.Add(1)
go func(i int) {
defer wg.Done()
fmt.Printf("并发数量:%d/n", i)
time.Sleep(time.Second)
}(i)
}
wg.Wait()
}
以上代码开启了 math.MaxInt32 个协程的并发,执行后可以看到结果直接 panic: too many concurrent operations on a single file or socket (max 1048575)
整个并发操作超出了系统最大值
goroutine 1228917 [running]:
internal/poll.(*fdMutex).rwlock(0xc0000ac0c0, 0x70?)
/root/.g/go/src/internal/poll/fd_mutex.go:147 +0x11b
internal/poll.(*FD).writeLock(...)
/root/.g/go/src/internal/poll/fd_mutex.go:239
internal/poll.(*FD).Write(0xc0000ac0c0, {0xc1325ab700, 0x18, 0x20})
/root/.g/go/src/internal/poll/fd_unix.go:370 +0x72
os.(*File).write(...)
/root/.g/go/src/os/file_posix.go:48
os.(*File).Write(0xc000012018, {0xc1325ab700?, 0x18, 0xc13469df90?})
/root/.g/go/src/os/file.go:175 +0x65
fmt.Fprintf({0x4b9fc8, 0xc000012018}, {0x49e2f0, 0x13}, {0xc121342f90, 0x1, 0x1})
/root/.g/go/src/fmt/print.go:225 +0x9b
fmt.Printf(...)
/root/.g/go/src/fmt/print.go:233
main.main.func1(0x0?)
/code/code.liaosirui.com/z-demo/go-demo/main.go:16 +0x9c
created by main.main
/code/code.liaosirui.com/z-demo/go-demo/main.go:14 +0x3c
panic: too many concurrent operations on a single file or socket (max 1048575)
对单个 file/socket 的并发操作个数超过了系统上限,这个报错是 fmt.Printf 函数引起的,fmt.Printf 将格式化后的字符串打印到屏幕,即标准输出;在 linux 系统中,标准输出也可以视为文件,内核(kernel)利用文件描述符(file descriptor)来访问文件,标准输出的文件描述符为 1,错误输出文件描述符为 2,标准输入的文件描述符为 0;简而言之,系统的资源被耗尽了
那如果将 fmt.Printf 这行代码去掉呢?那程序很可能会因为内存不足而崩溃;这一点更好理解,每个协程至少需要消耗 2KB 的空间,那么假设计算机的内存是 2GB,那么至多允许 2GB/2KB = 1M 个协程同时存在;那如果协程中还存在着其他需要分配内存的操作,那么允许并发执行的协程将会数量级地减少
package main
import (
"fmt"
"math"
"sync"
)
func main() {
task_chan := make(chan bool, 3) // 100 为 channel长度
wg := sync.WaitGroup{}
defer close(task_chan)
for i := 0; i < math.MaxInt; i++ {
wg.Add(1)
fmt.Println("go func ", i)
task_chan <- true
go func() {
<-task_chan
defer wg.Done()
}()
}
wg.Wait()
}
- 创建缓冲区大小为 3 的 channel,在没有被接收的情况下,至多发送 3 个消息则被阻塞;通过 channel 控制每次并发的数量;
- 开启协程前,设置 task_chan <- true,若缓存区满了则阻塞
- 协程任务执行完成后就释放缓冲区
- 等待所有的并发都处理结束后则函数结束;其实可以不使用 sync.WaitGroup;因使用 channel 控制并发处理的任务数量可以不用使用等待并发处理结束
设计原理
Go 语言中最常见的、也是经常被人提及的设计模式就是:不要通过共享内存的方式进行通信,而是应该通过通信的方式共享内存
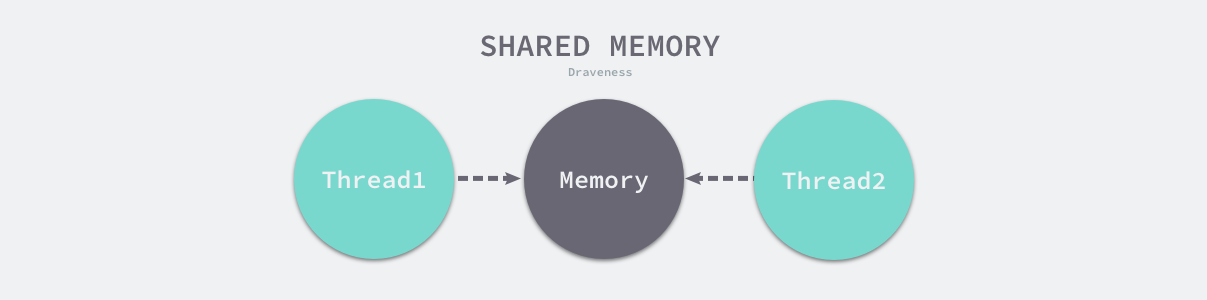
在很多主流的编程语言中,多个线程传递数据的方式一般都是共享内存,为了解决线程竞争,需要限制同一时间能够读写这些变量的线程数量,然而这与 Go 语言鼓励的设计并不相同
多线程使用共享内存传递数据:
虽然在 Go 语言中也能使用共享内存加互斥锁进行通信,但是 Go 语言提供了一种不同的并发模型,即通信顺序进程(Communicating sequential processes,CSP)
Goroutine 和 Channel 分别对应 CSP 中的实体和传递信息的媒介,Goroutine 之间会通过 Channel 传递数据
Goroutine 使用 Channel 传递数据:
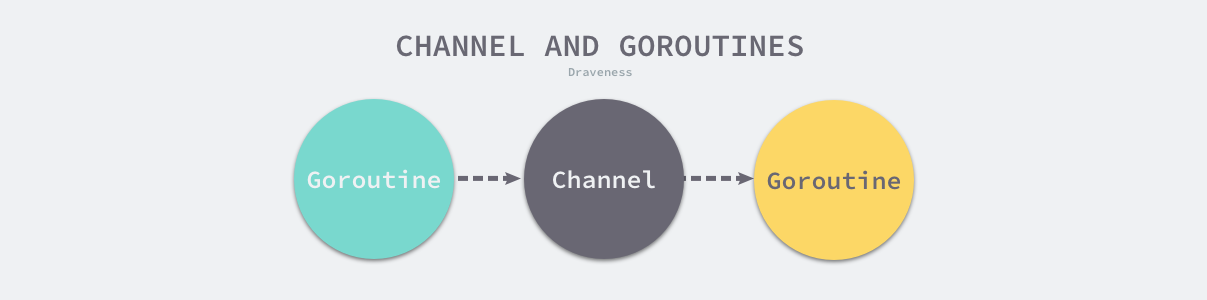
上图中的两个 Goroutine,一个会向 Channel 中发送数据,另一个会从 Channel 中接收数据,它们两者能够独立运行并不存在直接关联,但是能通过 Channel 间接完成通信
先入先出
目前的 Channel 收发操作均遵循了先进先出的设计
具体规则如下:
- 先从 Channel 读取数据的 Goroutine 会先接收到数据;
- 先向 Channel 发送数据的 Goroutine 会得到先发送数据的权利;
带缓冲区和不带缓冲区的 Channel 都会遵循先入先出发送和接收数据
无锁管道
锁是一种常见的并发控制技术,一般会将锁分成乐观锁和悲观锁,即乐观并发控制和悲观并发控制,无锁(lock-free)队列更准确的描述是使用乐观并发控制的队列
乐观并发控制也叫乐观锁,很多人都会误以为乐观锁是与悲观锁差不多,然而它并不是真正的锁,只是一种并发控制的思想

乐观并发控制本质上是基于验证的协议,使用原子指令 CAS(compare-and-swap 或者 compare-and-set)在多线程中同步数据,无锁队列的实现也依赖这一原子指令
Channel 在运行时的内部表示是 runtime.hchan,该结构体中包含了用于保护成员变量的互斥锁,从某种程度上说,Channel 是一个用于同步和通信的有锁队列,使用互斥锁解决程序中可能存在的线程竞争问题是很常见的,能很容易地实现有锁队列
然而锁导致的休眠和唤醒会带来额外的上下文切换,如果临界区过大,加锁解锁导致的额外开销就会成为性能瓶颈,1994 年的论文 Implementing lock-free queues 就研究了如何使用无锁的数据结构实现先进先出队列
而 Go 语言社区也在 2014 年提出了无锁 Channel 的实现方案,该方案将 Channel 分成了以下三种类型:
- 同步 Channel — 不需要缓冲区,发送方会直接将数据交给(Handoff)接收方;
- 异步 Channel — 基于环形缓存的传统生产者消费者模型;
chan struct{}类型的异步 Channel —struct{}类型不占用内存空间,不需要实现缓冲区和直接发送(Handoff)的语义;
这个提案的目的也不是实现完全无锁的队列,只是在一些关键路径上通过无锁提升 Channel 的性能
社区中已经有无锁 Channel 的实现,但是在实际的基准测试中,无锁队列在多核测试中的表现还需要进一步的改进
因为目前通过 CAS 实现的无锁 Channel 没有提供先进先出的特性,所以该提案暂时也被搁浅了
数据结构
Go 语言的 Channel 在运行时使用 runtime.hchan 结构体表示
在 Go 语言中创建新的 Channel 时,实际上创建的都是如下所示的结构:
源码 https://github.com/golang/go/blob/go1.20.2/src/runtime/chan.go#L33-L52
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
elemtype *_type // element type
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex
}
runtime.hchan 结构体中的五个字段 qcount、dataqsiz、buf、sendx、recv 构建底层的循环队列:
qcount— Channel 中的元素个数dataqsiz— Channel 中的循环队列的长度buf— Channel 的缓冲区数据指针sendx— Channel 的发送操作处理到的位置recvx— Channel 的接收操作处理到的位置
除此之外:
elemsize和elemtype分别表示当前 Channel 能够收发的元素类型和大小sendq和recvq存储了当前 Channel 由于缓冲区空间不足而阻塞的 Goroutine 列表
sendq 和 recvq 中这些等待队列使用双向链表 runtime.waitq 表示
源码 https://github.com/golang/go/blob/go1.20.2/src/runtime/chan.go#L54-L57
runtime.sudog 表示一个在等待列表中的 Goroutine,该结构中存储了两个分别指向前后 runtime.sudog 的指针以构成链表
链表中所有的元素都是 runtime.sudog 结构
源码:https://github.com/golang/go/blob/go1.20.2/src/runtime/runtime2.go#L338-L382
// sudog represents a g in a wait list, such as for sending/receiving
// on a channel.
//
// sudog is necessary because the g ↔ synchronization object relation
// is many-to-many. A g can be on many wait lists, so there may be
// many sudogs for one g; and many gs may be waiting on the same
// synchronization object, so there may be many sudogs for one object.
//
// sudogs are allocated from a special pool. Use acquireSudog and
// releaseSudog to allocate and free them.
type sudog struct {
// The following fields are protected by the hchan.lock of the
// channel this sudog is blocking on. shrinkstack depends on
// this for sudogs involved in channel ops.
g *g
next *sudog
prev *sudog
elem unsafe.Pointer // data element (may point to stack)
// The following fields are never accessed concurrently.
// For channels, waitlink is only accessed by g.
// For semaphores, all fields (including the ones above)
// are only accessed when holding a semaRoot lock.
acquiretime int64
releasetime int64
ticket uint32
// isSelect indicates g is participating in a select, so
// g.selectDone must be CAS'd to win the wake-up race.
isSelect bool
// success indicates whether communication over channel c
// succeeded. It is true if the goroutine was awoken because a
// value was delivered over channel c, and false if awoken
// because c was closed.
success bool
parent *sudog // semaRoot binary tree
waitlink *sudog // g.waiting list or semaRoot
waittail *sudog // semaRoot
c *hchan // channel
}
创建管道
Go 语言中所有 Channel 的创建都会使用 make 关键字,编译器会将 make(chan int, 10) 表达式转换成 OMAKE 类型的节点
源码 https://github.com/golang/go/blob/go1.20.2/src/cmd/compile/internal/typecheck/typecheck.go#L667-L669
// typecheck1 should ONLY be called from typecheck.
func typecheck1(n ir.Node, top int) ir.Node {
switch n.Op() {
// ...
case ir.OMAKE:
n := n.(*ir.CallExpr)
return tcMake(n)
// ...
}
并在类型检查阶段将 OMAKE 类型的节点转换成 OMAKECHAN 类型
源码 https://github.com/golang/go/blob/go1.20.2/src/cmd/compile/internal/typecheck/func.go#L702-L721
// tcMake typechecks an OMAKE node.
func tcMake(n *ir.CallExpr) ir.Node {
// ...
switch t.Kind() {
// ...
case types.TCHAN:
l = nil
if i < len(args) {
l = args[i]
i++
l = Expr(l)
l = DefaultLit(l, types.Types[types.TINT])
if l.Type() == nil {
n.SetType(nil)
return n
}
if !checkmake(t, "buffer", &l) {
n.SetType(nil)
return n
}
} else {
l = ir.NewInt(0)
}
nn = ir.NewMakeExpr(n.Pos(), ir.OMAKECHAN, l, nil)
}
// ...
}
if i < len(args) 是处理带缓冲区的异步 Channel,else 部分是处理不带缓冲区的同步 Channel
这一阶段会对传入 make 关键字的缓冲区大小进行检查,如果不向 make 传递表示缓冲区大小的参数,那么就会设置一个默认值 0,也就是当前的 Channel 不存在缓冲区
OMAKECHAN 类型的节点最终都会在 SSA 中间代码生成阶段之前被转换成调用 runtime.makechan 或者 runtime.makechan64 的函数
源码 https://github.com/golang/go/blob/go1.20.2/src/cmd/compile/internal/walk/expr.go#L286-L288
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
// ...
case ir.OMAKECHAN:
n := n.(*ir.MakeExpr)
return walkMakeChan(n, init)
// ...
}
}
源码 https://github.com/golang/go/blob/go1.20.2/src/cmd/compile/internal/walk/builtin.go#L260-L277
// walkMakeChan walks an OMAKECHAN node.
func walkMakeChan(n *ir.MakeExpr, init *ir.Nodes) ir.Node {
// When size fits into int, use makechan instead of
// makechan64, which is faster and shorter on 32 bit platforms.
size := n.Len
fnname := "makechan64"
argtype := types.Types[types.TINT64]
// Type checking guarantees that TIDEAL size is positive and fits in an int.
// The case of size overflow when converting TUINT or TUINTPTR to TINT
// will be handled by the negative range checks in makechan during runtime.
if size.Type().IsKind(types.TIDEAL) || size.Type().Size() <= types.Types[types.TUINT].Size() {
fnname = "makechan"
argtype = types.Types[types.TINT]
}
return mkcall1(chanfn(fnname, 1, n.Type()), n.Type(), init, reflectdata.MakeChanRType(base.Pos, n), typecheck.Conv(size, argtype))
}
runtime.makechan 和 runtime.makechan64 会根据传入的参数类型和缓冲区大小创建一个新的 Channel 结构,其中后者用于处理缓冲区大小大于 2 的 32 次方的情况,因为这在 Channel 中并不常见,所以重点关注 runtime.makechan:
源码 https://github.com/golang/go/blob/go1.20.2/src/runtime/chan.go#L72-L119
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// compiler checks this but be safe.
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
// Hchan does not contain pointers interesting for GC when elements stored in buf do not contain pointers.
// buf points into the same allocation, elemtype is persistent.
// SudoG's are referenced from their owning thread so they can't be collected.
// TODO(dvyukov,rlh): Rethink when collector can move allocated objects.
var c *hchan
switch {
case mem == 0:
// Queue or element size is zero.
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race detector uses this location for synchronization.
c.buf = c.raceaddr()
case elem.ptrdata == 0:
// Elements do not contain pointers.
// Allocate hchan and buf in one call.
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// Elements contain pointers.
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
lockInit(&c.lock, lockRankHchan)
if debugChan {
print("makechan: chan=", c, "; elemsize=", elem.size, "; dataqsiz=", size, "\n")
}
return c
}
上述代码根据 Channel 中收发元素的类型和缓冲区的大小初始化 runtime.hchan 和缓冲区:
- 如果当前 Channel 中不存在缓冲区,那么就只会为
runtime.hchan分配一段内存空间 - 如果当前 Channel 中存储的类型不是指针类型,会为当前的 Channel 和底层的数组分配一块连续的内存空间
- 在默认情况下会单独为
runtime.hchan和缓冲区分配内存
在函数的最后会统一更新 runtime.hchan 的 elemsize、elemtype 和 dataqsiz 几个字段
发送数据
当想要向 Channel 发送数据时,就需要使用 ch <- i 语句,编译器会将它解析成 OSEND 节点转换成 runtime.chansend1
源码 https://github.com/golang/go/blob/go1.20.2/src/cmd/compile/internal/walk/expr.go#L329-L331
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
// ...
case ir.OSEND:
n := n.(*ir.SendStmt)
return walkSend(n, init)
// ...
}
}
源码 https://github.com/golang/go/blob/go1.20.2/src/cmd/compile/internal/walk/expr.go#L825-L832
// walkSend walks an OSEND node.
func walkSend(n *ir.SendStmt, init *ir.Nodes) ir.Node {
n1 := n.Value
n1 = typecheck.AssignConv(n1, n.Chan.Type().Elem(), "chan send")
n1 = walkExpr(n1, init)
n1 = typecheck.NodAddr(n1)
return mkcall1(chanfn("chansend1", 2, n.Chan.Type()), nil, init, n.Chan, n1)
}
runtime.chansend1 只是调用了 runtime.chansend 并传入 Channel 和需要发送的数据
源码 https://github.com/golang/go/blob/go1.20.2/src/runtime/chan.go#L141-L146
// entry point for c <- x from compiled code.
//
//go:nosplit
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}
runtime.chansend 是向 Channel 中发送数据时一定会调用的函数,该函数包含了发送数据的全部逻辑,如果在调用时将 block 参数设置成 true,那么表示当前发送操作是阻塞的
源码 https://github.com/golang/go/blob/go1.20.2/src/runtime/chan.go#L148-L286
/*
* generic single channel send/recv
* If block is not nil,
* then the protocol will not
* sleep but return if it could
* not complete.
*
* sleep can wake up with g.param == nil
* when a channel involved in the sleep has
* been closed. it is easiest to loop and re-run
* the operation; we'll see that it's now closed.
*/
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
if c == nil {
if !block {
return false
}
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// ...
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
// ...
}
在发送数据的逻辑执行之前会先为当前 Channel 加锁,防止多个线程并发修改数据
如果 Channel 已经关闭,那么向该 Channel 发送数据时会报 “send on closed channel” 错误并中止程序
因为 runtime.chansend 函数的实现比较复杂,所以这里将该函数的执行过程分成以下的三个部分:
- 当存在等待的接收者时,通过
runtime.send直接将数据发送给阻塞的接收者 - 当缓冲区存在空余空间时,将发送的数据写入 Channel 的缓冲区
- 当不存在缓冲区或者缓冲区已满时,等待其他 Goroutine 从 Channel 接收数据
直接发送
如果目标 Channel 没有被关闭并且已经有处于读等待的 Goroutine,那么 runtime.chansend 会从接收队列 recvq 中取出最先陷入等待的 Goroutine 并直接向它发送数据:
/*
* generic single channel send/recv
* If block is not nil,
* then the protocol will not
* sleep but return if it could
* not complete.
*
* sleep can wake up with g.param == nil
* when a channel involved in the sleep has
* been closed. it is easiest to loop and re-run
* the operation; we'll see that it's now closed.
*/
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// ...
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
if sg := c.recvq.dequeue(); sg != nil {
// Found a waiting receiver. We pass the value we want to send
// directly to the receiver, bypassing the channel buffer (if any).
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
// ...
}
Channel 中存在等待数据的 Goroutine 时,直接向 Channel 发送数据的过程:
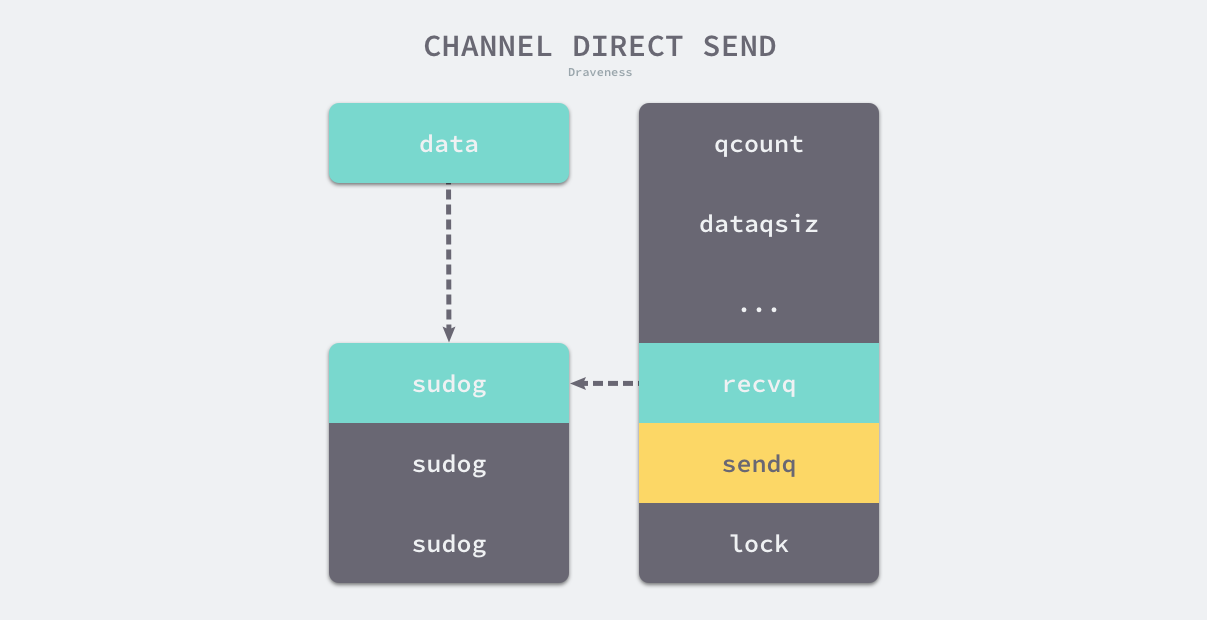
发送数据时会调用 runtime.send,该函数的执行可以分成两个部分:
- 调用
runtime.sendDirect将发送的数据直接拷贝到x = <-c表达式中变量x所在的内存地址上 - 调用
runtime.goready将等待接收数据的 Goroutine 标记成可运行状态Grunnable并把该 Goroutine 放到发送方所在的处理器的runnext上等待执行,该处理器在下一次调度时会立刻唤醒数据的接收方
源码 https://github.com/golang/go/blob/go1.20.2/src/runtime/chan.go#L288-L323
// send processes a send operation on an empty channel c.
// The value ep sent by the sender is copied to the receiver sg.
// The receiver is then woken up to go on its merry way.
// Channel c must be empty and locked. send unlocks c with unlockf.
// sg must already be dequeued from c.
// ep must be non-nil and point to the heap or the caller's stack.
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if raceenabled {
if c.dataqsiz == 0 {
racesync(c, sg)
} else {
// Pretend we go through the buffer, even though
// we copy directly. Note that we need to increment
// the head/tail locations only when raceenabled.
racenotify(c, c.recvx, nil)
racenotify(c, c.recvx, sg)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
}
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
需要注意的是,发送数据的过程只是将接收方的 Goroutine 放到了处理器的 runnext 中,程序没有立刻执行该 Goroutine
缓冲区
如果创建的 Channel 包含缓冲区并且 Channel 中的数据没有装满,会执行下面这段代码:
/*
* generic single channel send/recv
* If block is not nil,
* then the protocol will not
* sleep but return if it could
* not complete.
*
* sleep can wake up with g.param == nil
* when a channel involved in the sleep has
* been closed. it is easiest to loop and re-run
* the operation; we'll see that it's now closed.
*/
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// ...
if c.qcount < c.dataqsiz {
// Space is available in the channel buffer. Enqueue the element to send.
qp := chanbuf(c, c.sendx)
if raceenabled {
racenotify(c, c.sendx, nil)
}
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}
// ...
}
在这里首先会使用 runtime.chanbuf 计算出下一个可以存储数据的位置(循环队列),然后通过 runtime.typedmemmove 将发送的数据拷贝到缓冲区中并增加 sendx 索引和 qcount 计数器
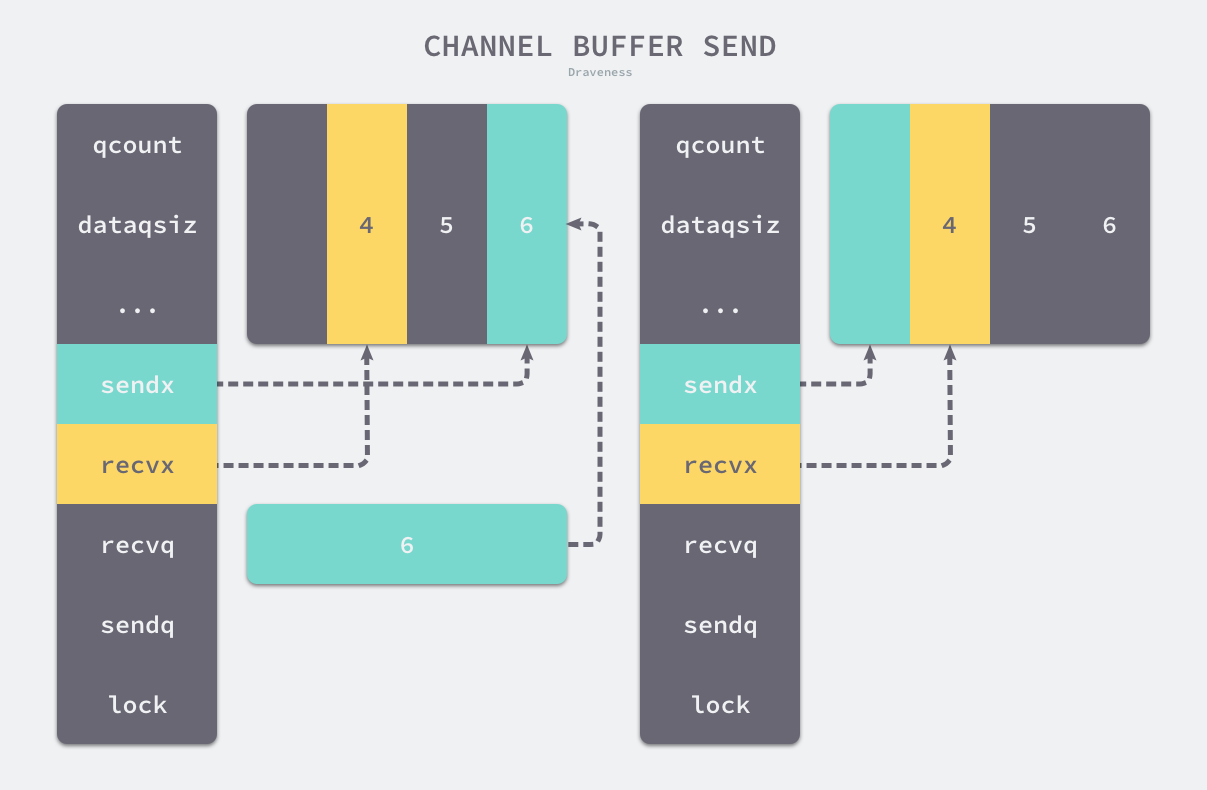
如果当前 Channel 的缓冲区未满,向 Channel 发送的数据会存储在 Channel 的 sendx 索引所在的位置并将 sendx 索引加 1
因为这里的 buf 是一个循环数组,所以当 sendx 等于 dataqsiz 时会重新回到数组开始的位置
阻塞发送
当 Channel 没有接收者能够处理数据时,向 Channel 发送数据会被下游阻塞,当然使用 select 关键字可以向 Channel 非阻塞地发送消息
向 Channel 阻塞地发送数据会执行下面的代码,可以简单梳理一下这段代码的逻辑:
- 调用
runtime.getg获取发送数据使用的 Goroutine - 执行
runtime.acquireSudog获取runtime.sudog结构并设置这一次阻塞发送的相关信息,例如发送的 Channel、是否在 select 中和待发送数据的内存地址等 - 将刚刚创建并初始化的
runtime.sudog加入发送等待队列,并设置到当前 Goroutine 的waiting上,表示 Goroutine 正在等待该sudog准备就绪 - 调用
runtime.goparkunlock将当前的 Goroutine 陷入沉睡等待唤醒 - 被调度器唤醒后会执行一些收尾工作,将一些属性置零并且释放
runtime.sudog结构体
函数在最后会返回 true 表示这次已经成功向 Channel 发送了数据
/*
* generic single channel send/recv
* If block is not nil,
* then the protocol will not
* sleep but return if it could
* not complete.
*
* sleep can wake up with g.param == nil
* when a channel involved in the sleep has
* been closed. it is easiest to loop and re-run
* the operation; we'll see that it's now closed.
*/
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// ...
if !block {
unlock(&c.lock)
return false
}
// Block on the channel. Some receiver will complete our operation for us.
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// No stack splits between assigning elem and enqueuing mysg
// on gp.waiting where copystack can find it.
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
c.sendq.enqueue(mysg)
// Signal to anyone trying to shrink our stack that we're about
// to park on a channel. The window between when this G's status
// changes and when we set gp.activeStackChans is not safe for
// stack shrinking.
gp.parkingOnChan.Store(true)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)
// Ensure the value being sent is kept alive until the
// receiver copies it out. The sudog has a pointer to the
// stack object, but sudogs aren't considered as roots of the
// stack tracer.
KeepAlive(ep)
// someone woke us up.
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
closed := !mysg.success
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
mysg.c = nil
releaseSudog(mysg)
if closed {
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
panic(plainError("send on closed channel"))
}
return true
}
总结
在这里可以简单梳理和总结一下使用 ch <- i 表达式向 Channel 发送数据时遇到的几种情况:
- 如果当前 Channel 的
recvq上存在已经被阻塞的 Goroutine,那么会直接将数据发送给当前 Goroutine 并将其设置成下一个运行的 Goroutine - 如果 Channel 存在缓冲区并且其中还有空闲的容量,会直接将数据存储到缓冲区
sendx所在的位置上 - 如果不满足上面的两种情况,会创建一个
runtime.sudog结构并将其加入 Channel 的sendq队列中,当前 Goroutine 也会陷入阻塞等待其他的协程从 Channel 接收数据
发送数据的过程中包含几个会触发 Goroutine 调度的时机:
- 发送数据时发现 Channel 上存在等待接收数据的 Goroutine,立刻设置处理器的
runnext属性,但是并不会立刻触发调度 - 发送数据时并没有找到接收方并且缓冲区已经满了,这时会将自己加入 Channel 的
sendq队列并调用runtime.goparkunlock触发 Goroutine 的调度让出处理器的使用权
接收数据
Channel 操作的另一方:接收数据
Go 语言中可以使用两种不同的方式去接收 Channel 中的数据:
前者经过编译器的处理会变成 ORECV 类型的节点,后者会在类型检查阶段被转换成 OAS2RECV 类型
源码
-
https://github.com/golang/go/blob/go1.20.2/src/cmd/compile/internal/walk/expr.go#L187-L188
-
https://github.com/golang/go/blob/go1.20.2/src/cmd/compile/internal/walk/expr.go#L251-L253
- https://github.com/golang/go/blob/go1.20.2/src/cmd/compile/internal/walk/expr.go#L199-L203
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
// ...
case ir.OAS, ir.OASOP:
return walkAssign(init, n)
// ...
case ir.ORECV:
base.Fatalf("walkExpr ORECV") // should see inside OAS only
panic("unreachable")
// ...
// x, y = <-c
// order.stmt made sure x is addressable or blank.
case ir.OAS2RECV:
n := n.(*ir.AssignListStmt)
return walkAssignRecv(init, n)
// ...
}
}
源码 https://github.com/golang/go/blob/go1.20.2/src/cmd/compile/internal/walk/assign.go#L74-L82
// walkAssign walks an OAS (AssignExpr) or OASOP (AssignOpExpr) node.
func walkAssign(init *ir.Nodes, n ir.Node) ir.Node {
switch as.Y.Op() {
// ...
case ir.ORECV:
// x = <-c; as.Left is x, as.Right.Left is c.
// order.stmt made sure x is addressable.
recv := as.Y.(*ir.UnaryExpr)
recv.X = walkExpr(recv.X, init)
n1 := typecheck.NodAddr(as.X)
r := recv.X // the channel
return mkcall1(chanfn("chanrecv1", 2, r.Type()), nil, init, r, n1)
}
// ...
}
源码 https://github.com/golang/go/blob/go1.20.2/src/cmd/compile/internal/walk/assign.go#L205-L222
// walkAssignRecv walks an OAS2RECV node.
func walkAssignRecv(init *ir.Nodes, n *ir.AssignListStmt) ir.Node {
init.Append(ir.TakeInit(n)...)
r := n.Rhs[0].(*ir.UnaryExpr) // recv
walkExprListSafe(n.Lhs, init)
r.X = walkExpr(r.X, init)
var n1 ir.Node
if ir.IsBlank(n.Lhs[0]) {
n1 = typecheck.NodNil()
} else {
n1 = typecheck.NodAddr(n.Lhs[0])
}
fn := chanfn("chanrecv2", 2, r.X.Type())
ok := n.Lhs[1]
call := mkcall1(fn, types.Types[types.TBOOL], init, r.X, n1)
return typecheck.Stmt(ir.NewAssignStmt(base.Pos, ok, call))
}
数据的接收操作遵循以下的路线图:
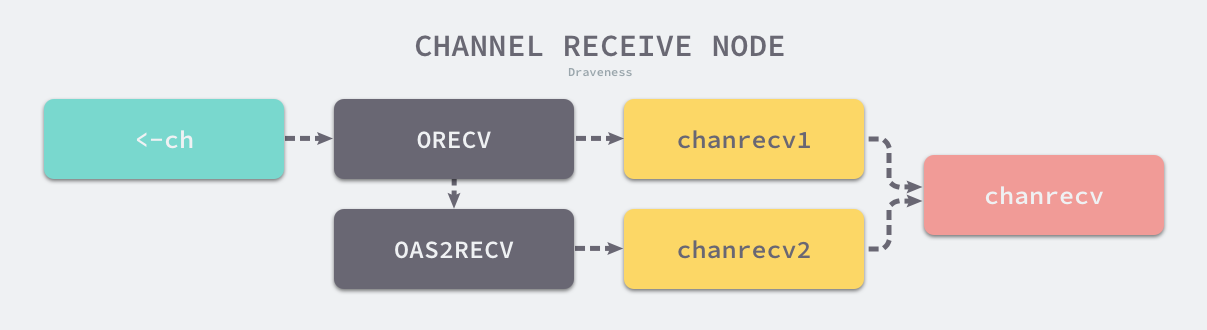
虽然不同的接收方式会被转换成 runtime.chanrecv1 和 runtime.chanrecv2 两种不同函数的调用,但是这两个函数最终还是会调用 runtime.chanrecv
源码 https://github.com/golang/go/blob/go1.20.2/src/runtime/chan.go#L438-L449
// entry points for <- c from compiled code.
//
//go:nosplit
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
//go:nosplit
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {
_, received = chanrecv(c, elem, true)
return
}
当从一个空 Channel 接收数据时会直接调用 runtime.gopark 让出处理器的使用权
源码 https://github.com/golang/go/blob/go1.20.2/src/runtime/chan.go#L513-L535
// chanrecv receives on channel c and writes the received data to ep.
// ep may be nil, in which case received data is ignored.
// If block == false and no elements are available, returns (false, false).
// Otherwise, if c is closed, zeros *ep and returns (true, false).
// Otherwise, fills in *ep with an element and returns (true, true).
// A non-nil ep must point to the heap or the caller's stack.
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// raceenabled: don't need to check ep, as it is always on the stack
// or is new memory allocated by reflect.
if debugChan {
print("chanrecv: chan=", c, "\n")
}
if c == nil {
if !block {
return
}
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// ...
lock(&c.lock)
if c.closed != 0 {
if c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
// The channel has been closed, but the channel's buffer have data.
} else {
// Just found waiting sender with not closed.
if sg := c.sendq.dequeue(); sg != nil {
// Found a waiting sender. If buffer is size 0, receive value
// directly from sender. Otherwise, receive from head of queue
// and add sender's value to the tail of the queue (both map to
// the same buffer slot because the queue is full).
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
}
// ...
}
如果当前 Channel 已经被关闭并且缓冲区中不存在任何数据,那么会清除 ep 指针中的数据并立刻返回
除了上述两种特殊情况,使用 runtime.chanrecv 从 Channel 接收数据时还包含以下三种不同情况:
- 当存在等待的发送者时,通过
runtime.recv从阻塞的发送者或者缓冲区中获取数据 - 当缓冲区存在数据时,从 Channel 的缓冲区中接收数据
- 当缓冲区中不存在数据时,等待其他 Goroutine 向 Channel 发送数据
直接接收
当 Channel 的 sendq 队列中包含处于等待状态的 Goroutine 时,该函数会取出队列头等待的 Goroutine,处理的逻辑和发送时相差无几,只是发送数据时调用的是 runtime.send 函数,而接收数据时使用 runtime.recv
源码 https://github.com/golang/go/blob/go1.20.2/src/runtime/chan.go#L526-L533
// chanrecv receives on channel c and writes the received data to ep.
// ep may be nil, in which case received data is ignored.
// If block == false and no elements are available, returns (false, false).
// Otherwise, if c is closed, zeros *ep and returns (true, false).
// Otherwise, fills in *ep with an element and returns (true, true).
// A non-nil ep must point to the heap or the caller's stack.
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// ...
lock(&c.lock)
if c.closed != 0 {
// ...
} else {
// Just found waiting sender with not closed.
if sg := c.sendq.dequeue(); sg != nil {
// Found a waiting sender. If buffer is size 0, receive value
// directly from sender. Otherwise, receive from head of queue
// and add sender's value to the tail of the queue (both map to
// the same buffer slot because the queue is full).
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
}
// ...
}
runtime.recv 的实现比较复杂
源码 https://github.com/golang/go/blob/go1.20.2/src/runtime/chan.go#L601-L655
// recv processes a receive operation on a full channel c.
// There are 2 parts:
// 1. The value sent by the sender sg is put into the channel
// and the sender is woken up to go on its merry way.
// 2. The value received by the receiver (the current G) is
// written to ep.
//
// For synchronous channels, both values are the same.
// For asynchronous channels, the receiver gets its data from
// the channel buffer and the sender's data is put in the
// channel buffer.
// Channel c must be full and locked. recv unlocks c with unlockf.
// sg must already be dequeued from c.
// A non-nil ep must point to the heap or the caller's stack.
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if c.dataqsiz == 0 {
if raceenabled {
racesync(c, sg)
}
if ep != nil {
// copy data from sender
recvDirect(c.elemtype, sg, ep)
}
} else {
// Queue is full. Take the item at the
// head of the queue. Make the sender enqueue
// its item at the tail of the queue. Since the
// queue is full, those are both the same slot.
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
racenotify(c, c.recvx, sg)
}
// copy data from queue to receiver
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// copy data from sender to queue
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
sg.elem = nil
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
Go 该函数会根据缓冲区的大小分别处理不同的情况:
- 如果 Channel 不存在缓冲区
- 调用
runtime.recvDirect将 Channel 发送队列中 Goroutine 存储的elem数据拷贝到目标内存地址中 - 如果 Channel 存在缓冲区
- 将队列中的数据拷贝到接收方的内存地址
- 将发送队列头的数据拷贝到缓冲区中,释放一个阻塞的发送方
无论发生哪种情况,运行时都会调用 runtime.goready 将当前处理器的 runnext 设置成发送数据的 Goroutine,在调度器下一次调度时将阻塞的发送方唤醒
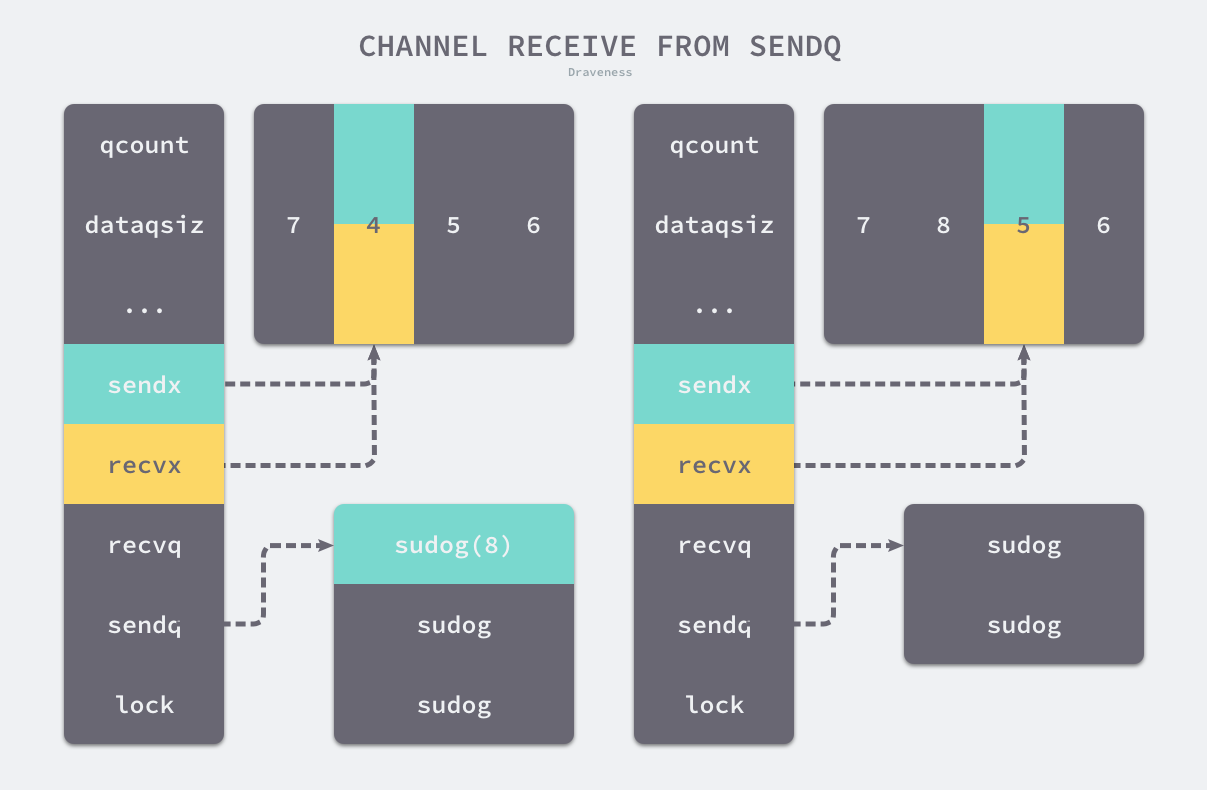
上图展示了 Channel 在缓冲区已经没有空间并且发送队列中存在等待的 Goroutine 时,运行 <-ch 的执行过程
发送队列头的 runtime.sudog 中的元素会替换接收索引 recvx 所在位置的元素,原有的元素会被拷贝到接收数据的变量对应的内存空间上
缓冲区
当 Channel 的缓冲区中已经包含数据时,从 Channel 中接收数据会直接从缓冲区中 recvx 的索引位置中取出数据进行处理:
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if c.dataqsiz == 0 {
// ...
} else {
// Queue is full. Take the item at the
// head of the queue. Make the sender enqueue
// its item at the tail of the queue. Since the
// queue is full, those are both the same slot.
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
racenotify(c, c.recvx, sg)
}
// copy data from queue to receiver
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// copy data from sender to queue
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
sg.elem = nil
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
}
如果接收数据的内存地址不为空,那么会使用 runtime.typedmemmove 将缓冲区中的数据拷贝到内存中、清除队列中的数据并完成收尾工作
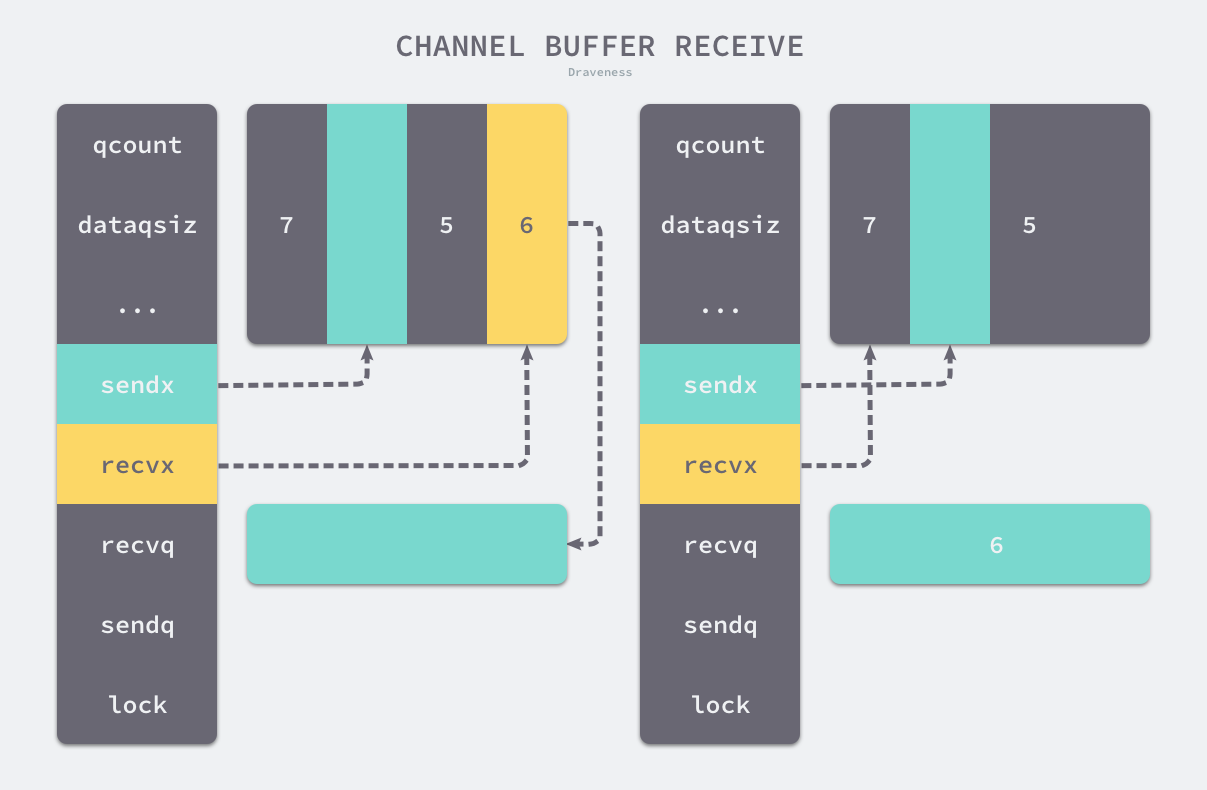
收尾工作包括递增 recvx,一旦发现索引超过了 Channel 的容量时,会将它归零重置循环队列的索引;除此之外,该函数还会减少 qcount 计数器并释放持有 Channel 的锁
阻塞接收
当 Channel 的发送队列中不存在等待的 Goroutine 并且缓冲区中也不存在任何数据时,从管道中接收数据的操作会变成阻塞的,然而不是所有的接收操作都是阻塞的,与 select 语句结合使用时就可能会使用到非阻塞的接收操作
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// ...
if !block {
unlock(&c.lock)
return false, false
}
// no sender available: block on this channel.
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// No stack splits between assigning elem and enqueuing mysg
// on gp.waiting where copystack can find it.
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
c.recvq.enqueue(mysg)
// Signal to anyone trying to shrink our stack that we're about
// to park on a channel. The window between when this G's status
// changes and when we set gp.activeStackChans is not safe for
// stack shrinking.
gp.parkingOnChan.Store(true)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)
// someone woke us up
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
success := mysg.success
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true, success
}
在正常的接收场景中,会使用 runtime.sudog 将当前 Goroutine 包装成一个处于等待状态的 Goroutine 并将其加入到接收队列中
完成入队之后,上述代码还会调用 runtime.goparkunlock 立刻触发 Goroutine 的调度,让出处理器的使用权并等待调度器的调度
总结
从 Channel 中接收数据时可能会发生的五种情况:
- 如果 Channel 为空,那么会直接调用
runtime.gopark挂起当前 Goroutine - 如果 Channel 已经关闭并且缓冲区没有任何数据,
runtime.chanrecv会直接返回 - 如果 Channel 的
sendq队列中存在挂起的 Goroutine,会将recvx索引所在的数据拷贝到接收变量所在的内存空间上并将sendq队列中 Goroutine 的数据拷贝到缓冲区 - 如果 Channel 的缓冲区中包含数据,那么直接读取
recvx索引对应的数据 - 在默认情况下会挂起当前的 Goroutine,将
runtime.sudog结构加入recvq队列并陷入休眠等待调度器的唤醒;
总结一下从 Channel 接收数据时,会触发 Goroutine 调度的两个时机:
- 当 Channel 为空时
- 当缓冲区中不存在数据并且也不存在数据的发送者时
关闭通道
编译器会将用于关闭管道的 close 关键字转换成 OCLOSE 节点以及 runtime.closechan 函数
源码 https://github.com/golang/go/blob/go1.20.2/src/cmd/compile/internal/walk/expr.go#L282-L284
源码 https://github.com/golang/go/blob/go1.20.2/src/cmd/compile/internal/walk/builtin.go#L133-L139
// walkClose walks an OCLOSE node.
func walkClose(n *ir.UnaryExpr, init *ir.Nodes) ir.Node {
// cannot use chanfn - closechan takes any, not chan any
fn := typecheck.LookupRuntime("closechan")
fn = typecheck.SubstArgTypes(fn, n.X.Type())
return mkcall1(fn, nil, init, n.X)
}
当 Channel 是一个空指针或者已经被关闭时,Go 语言运行时都会直接崩溃并抛出异常:
源码 https://github.com/golang/go/blob/go1.20.2/src/runtime/chan.go#L357-L426
func closechan(c *hchan) {
if c == nil {
panic(plainError("close of nil channel"))
}
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
if raceenabled {
callerpc := getcallerpc()
racewritepc(c.raceaddr(), callerpc, abi.FuncPCABIInternal(closechan))
racerelease(c.raceaddr())
}
c.closed = 1
var glist gList
// release all readers
for {
sg := c.recvq.dequeue()
if sg == nil {
break
}
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem)
sg.elem = nil
}
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
// release all writers (they will panic)
for {
sg := c.sendq.dequeue()
if sg == nil {
break
}
sg.elem = nil
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
unlock(&c.lock)
// Ready all Gs now that we've dropped the channel lock.
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}
处理完了这些异常的情况之后就可以开始执行关闭 Channel 的逻辑了,将 recvq 和 sendq 两个队列中的数据加入到 Goroutine 列表 gList 中,与此同时该函数会清除所有 runtime.sudog 上未被处理的元素
该函数在最后会为所有被阻塞的 Goroutine 调用 runtime.goready 触发调度