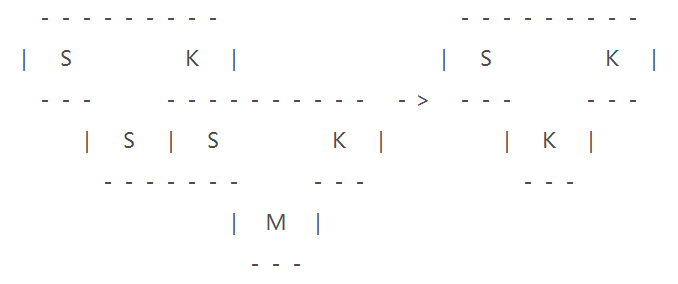编译系统结构
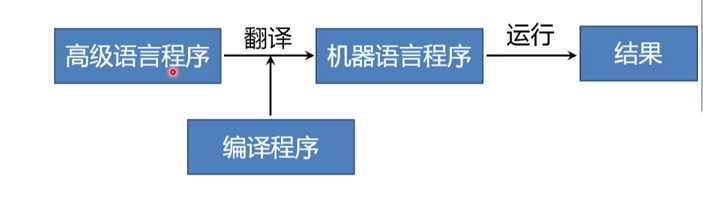
编译型和解释型程序
编译程序和解释程序区别如下:
- 编译程序由目标程序,解释程序没有目标程序
- 编译程序运行效率高
- 解释程序便于人机对话
编译型程序
编译程序是一种翻译程序,它特指把某种高级程序设计语言翻译成与之等价的具体计算上的低级程序设计语言
编译程序包括“编译阶段”和“运行阶段”两部分:
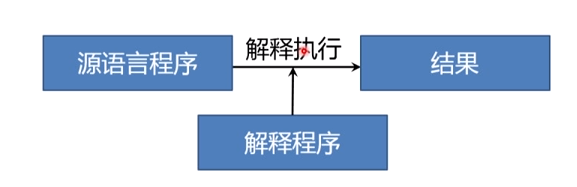
解释型程序
解释程序也是一种翻译程序,它将源语言书写的源程序作为输入,解释一句后就提交计算机执行一句,并不形成目标程序
编译程序执行过程
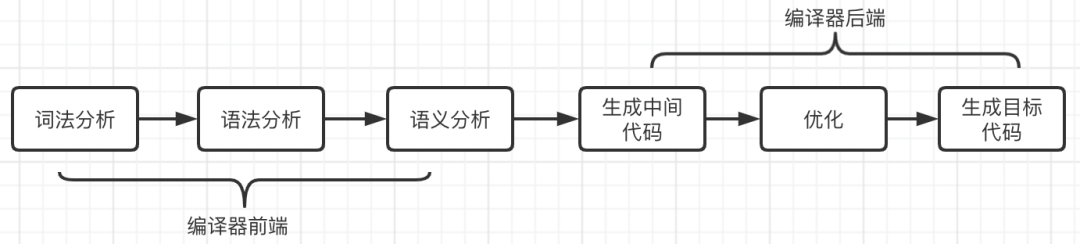
在编译的过程中,编译器会进行一系列的操作,编译器可看成多个阶段构成的"流水线"结构,如下图:
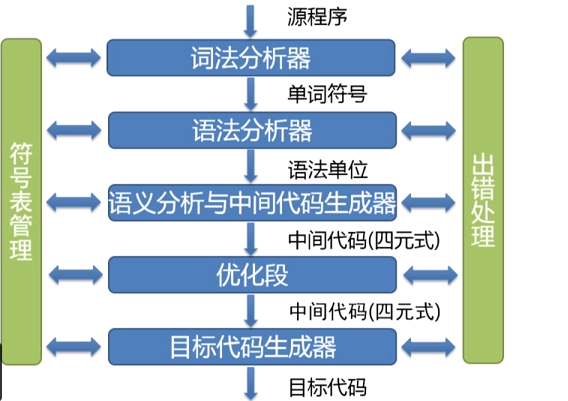
具体的步骤流程如下:
- 词法分析:从左到右读入源程序的每个字符,对构成源程序的字符流进行扫描和分解,从而辨识出一个个的单词(也叫单词符合或者符合)
- 语法分析: 依据语言的语法规则,确定源程序的输入串是否构成一个语法上正确的程序;最终将单词序列分解为各类语法短语(也叫语法单位),如“程序”、“语句”、“表达式”等
- 语义分析: 审查源程序有无语义错误,为代码生成阶段收集类型信息
- 中间代码生成:在语法分析和语义分析之后,将源程序变成一种“内部表示形式”
- 优化:对中间代码进行变换或者改造,使之更为高效(时间、空间)
- 目标代码生成(中间代码转低级语言代码,需要考虑硬件系统结构):把中间代码变换成特定机器上的绝对指令代码或者可重定位的机器指令代码或者汇编指令代码
符号表管理和出错处理,此结构与每个阶段都有联系
其中在执行过程中将产生单词串 TOKEN、语法树、语义树和优化语义树等
出错处理举例:
- 词法错误:非法字符,关键字或标识符的拼写错误
- 语法错误:语法结构出错,if / endif 不匹配,缺分号
- 语义错误:死循环,零除数,其他逻辑错误
编译过程的分解
编译器具有非常模块化的高层结构,可抽象的多个阶段(phase)
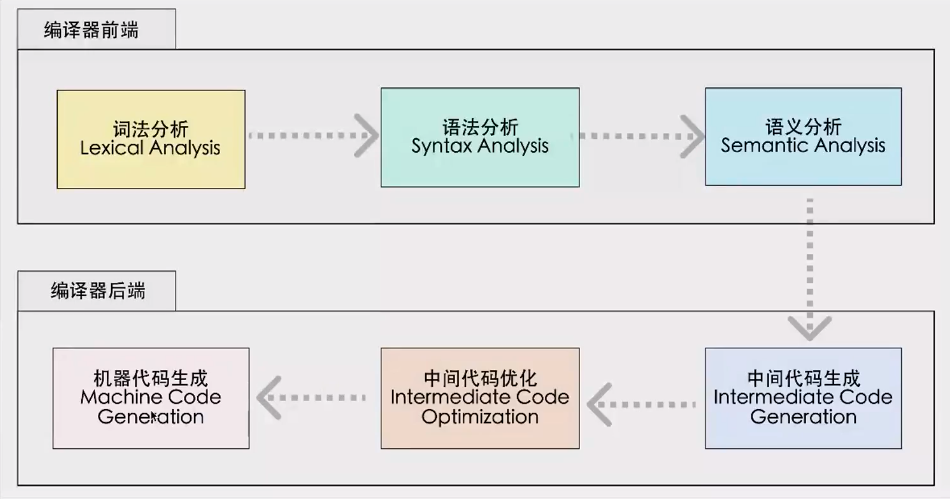
由于词法分析,语法分析与中间代码产生与目标机器无关,因此可以以中间代码为分界线,将编译过程分解为:
- 编译前端
- 编译后端
能够使程序更加清晰,优化更加充分,提高程序的可移植性
编译前端
源程序通过词法编译器、语法编译器、中间代码产生以及与机器无关优化的处理,实现从源语言到中间语言的转换
编译后端
与机器有关的优化以及目标代码的产生,实现中间语言到目标代码的转换
遍的概念
遍(趟):是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程;每一遍扫视可完成上述一个阶段或多个阶段的工作
编译的遍数
一个编译过程可由一遍、两遍或多遍完成
- 例如一遍可以只完成词法分析工作;一遍完成词法分析和语法分析工作
- 甚至一遍完成整个编译工作
对于多遍的编译程序,第一遍的输入是用户书写的源程序,最后一遍的输出是目标语言程序,其余是上一遍的输出为下一遍的输入
遍数多一点,整个编译程序的逻辑结构可能清晰些,但遍数多即意味着增加读写中间文件的次数,势必消耗较多时间,一般会比一遍的编译要慢
根据语言和环境的不同,一般情况是分成两遍:
影响遍数的因素
在实际的编译系统的设计中,编译的几个阶段的工作究竟应该怎样组合,即编译程序究竟分成几遍,参考的因素主要是:
- 源语言:源语言的结构直接影响编译的遍的划分;像 PL/1 或 ALGOL 68 那样的语言,允许名字的说明出现在名字的使用之后,那么在看到名字之前是不便为包含该名字的表达式生成代码的,这种语言的编译程序至少分成两遍才容易生成代码
- 机器(目标机)的特征:即编译程序工作的环境也影响编译程序的遍数的划分
编译器的自举和移植
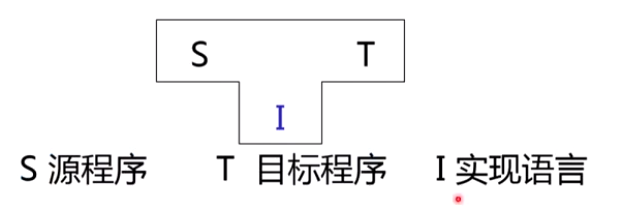
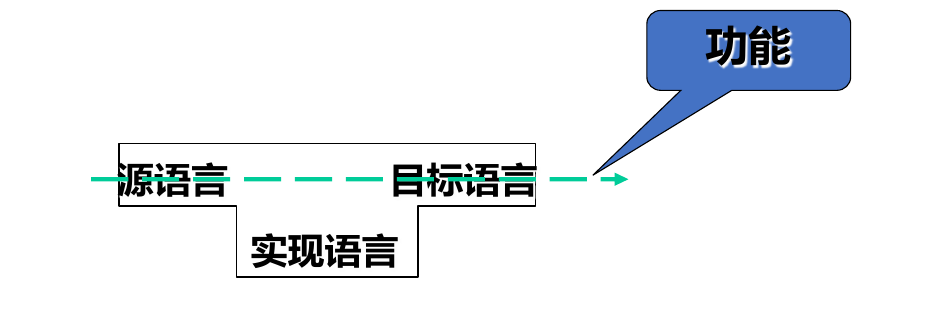
编译过程可用表示 T-Diagram 图表示,通过 I 代码 将 S 语言 转换成能够在 T 机器 上运行的文件:
即:
编译程序的生成
方式一:通过已有的高级语言去编写新的高级语言的程序
在 A 机器上有一个能够将 L 语言翻译成 A 机器的机器代码的 P1 代码,那么可以用 L 语言去编写一个程序 PA (该程序的目的是实现 P 语言到 A 机器的编译),从而使得高级语言 P 可以在 A 机器上执行
编译示意图过程如下:
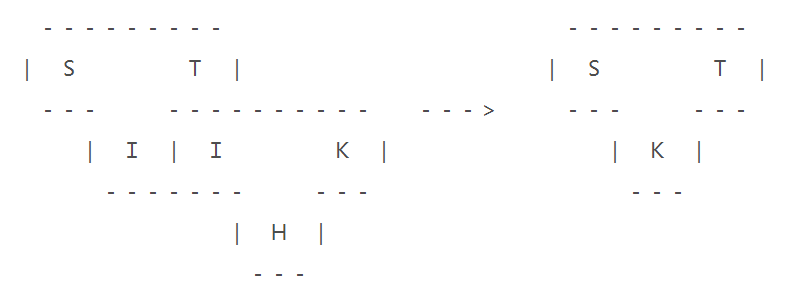
用 H 编译器实现 I 语言到 K 语言的转换,在此基础上,用 I 语言编写一个编译器 I,实现从 S 语言到 T 语言的转换,借助 H 编译器,可以将 I 编译器先转换为基于 K 语言的编译器,实现 S 到 T 语言基于 K 编译器的转换,类似于 CPython 编译器的原理
方式二:通过自编译方式,通过不断的对编译器进行功能的增加,从而达到一个符合所有条件的最终编译器
编译程序的自举
自举就是用该机器 A 的低级语言去编写一个简单的微型编译器 A1,然后在该微型编译器的基础上增加更多功能,形成具有更多功能的编译器 A2,用 A2 去进行编译得到最终需要的编译器,这便是编译器的自举
还是需要用M语言写一个具有很小功能的S编译器,然后用其去编译加入了更多功能的编译器,然后用编译出来的更多功能的编译器去编译,这样就得到了最终需要的编译器,这便是自举
过程示意图如下:

编译程序的移植
编译程序的移植,其目的是解决高级语言的跨平台性,使同一种语言能够在不同的机器上运行
移植的关键在于产生交叉编译器

已知有一个 M 编译器,可以在 M 机器上编译 S 语言,因此,可用 S 语言去编写一个编译器 S,在 K 机器上能够对 S 语言进行编译,又因为 S 语言可用 M 语言编译,因此将 S 编译器用 M 编译器进行编译得到 M 程序,实现 S 语言在 K 机器上的编译过程,此时 M 便是交叉编译器,得到交叉编译器之后,便可以编译在 K 机器上的 S 编译器了,将编译器 S 编译成 K 语言的编译器 K,便可以得到在 K 机器上运行的 K 编译器了
如图所示: