ClickHouse
ClickHouse 简介
ClickHouse 是一个面向列的数据库管理系统(DBMS),用于查询的在线分析处理(OLAP)
- Github 仓库:https://github.com/ClickHouse/ClickHouse
OLAP
OLAP(在线分析处理),是指对大量数据集进行复杂计算(例如,聚合、字符串处理、算数)的 SQL 查询。与仅在每次查询中读取和写入少量行的事务查询(或 OLTP,在线事务处理)不同,分析查询通常处理数十亿和数万亿行数据。
行式存储与列式存储
在行式数据库中,连续的表行是依次存储的。这种布局允许快速检索行,因为每行的列值一起存储。
ClickHouse 是一个面向列的数据库。在这种系统中,表被存储为列的集合,即每列的值依次存储。这种布局使恢复单个行变得更加困难(因为现在行值之间存在间隙),但列操作,例如过滤或聚合,变得比行式数据库要快得多。
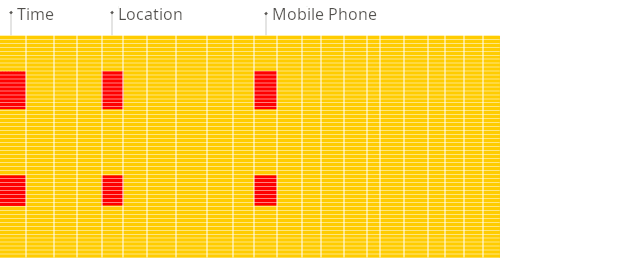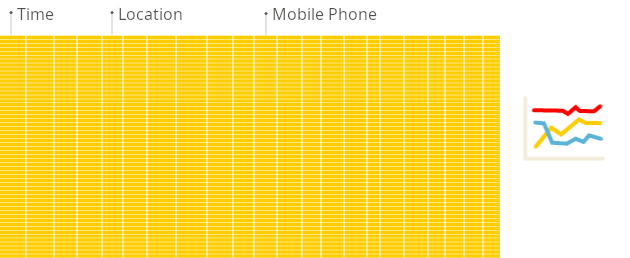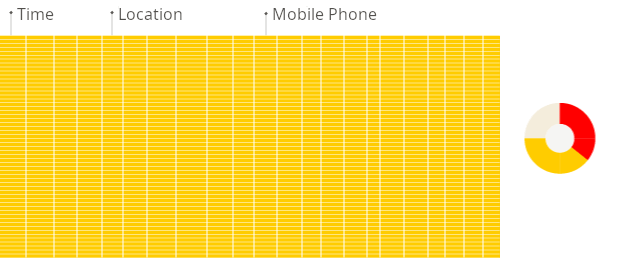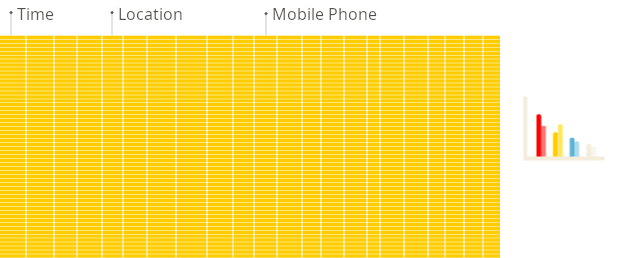
(1)行式 DBMS
在行式数据库中,尽管上述查询只处理了少数现有列,但系统仍然需要将来自其他现有列的数据从磁盘加载到内存中。原因是数据以称为块的块形式存储在磁盘上(通常为固定大小,例如 4 KB 或 8 KB)。块是从磁盘读取到内存的最小数据单位。当应用程序或数据库请求数据时,操作系统的磁盘 I/O 子系统会从磁盘读取所需的块。即使只需要块的一部分,整个块也会被读入内存(这是由于磁盘和文件系统的设计):

(2)列式 DBMS
由于每列的值被依次存储在磁盘上,因此在运行上述查询时不会加载不必要的数据。 由于块状存储和从磁盘到内存的传输与分析查询的数据访问模式相一致,只读取查询所需的列,从而避免了对未使用数据的不必要 I/O。这与行式存储相比,性能要快得多,在行式存储中,会读取整个行(包括不相关的列):
端口
- 8123 端口
这是 ClickHouse 的 HTTP 端口,用于提供基于 HTTP 的查询接口。通过该端口可以使用 HTTP 请求与 ClickHouse 服务器进行交互执行查询、获取查询结果等操作。
- 9000 端口
这是 ClickHouse 的默认服务器端口,用于客户端与 ClickHouse 服务器进行通信。客户端应用程序可以通过该端口连接到 ClickHouse 服务器,并执行查询、插入和更新等数据库操作。
- 9004 端口
这是 ClickHouse 的分布式表引擎(Distributed Table Engine)使用的端口。当 ClickHouse 使用分布式表引擎进行数据分片和分布式查询时,节点之间会通过该端口进行通信。
- 9005 端口
这是 ClickHouse 的分布式表引擎(Distributed Table Engine)使用的备份(Replica)端口。当 ClickHouse 使用分布式表引擎进行数据备份和冗余存储时,节点之间会通过该端口进行数据同步和复制。
- 9009 端口
这是 ClickHouse 的远程服务器管理(Remote Server Management)端口。通过该端口,可以使用 ClickHouse 客户端工具(如 clickhouse-client)远程管理 ClickHouse 服务器,包括执行管理命令、配置修改等操作。
快速入门
文档地址:https://clickhouse.com/docs/zh/getting-started/quick-start
使用 CREATE TABLE 定义新表。在 ClickHouse 中,典型的 SQL DDL 命令同样适用,唯一的补充是 ClickHouse 中的表需要一个 ENGINE 子句。当创建表时可以通过 PARTITION BY 语句指定以某一个或多个字段作为分区字段
CREATE TABLE my_first_table
(
user_id UInt32,
message String,
timestamp DateTime,
metric Float32
)
ENGINE = MergeTree
PRIMARY KEY (user_id, timestamp)
插入数据
可以在 ClickHouse 中使用熟悉的 INSERT INTO TABLE 命令,但重要的是要理解,每次插入 MergeTree 表时,ClickHouse 会在存储中创建一个我们称之为 part 的部分。这些部分稍后会在后台由 ClickHouse 合并。
在 ClickHouse 中,我们尽量批量插入大量行(一次数以万计或甚至数百万计),以减少后台合并所需的 parts 数量。
INSERT INTO my_first_table (user_id, message, timestamp, metric) VALUES
(101, 'Hello, ClickHouse!', now(), -1.0 ),
(102, 'Insert a lot of rows per batch', yesterday(), 1.41421 ),
(102, 'Sort your data based on your commonly-used queries', today(), 2.718 ),
(101, 'Granules are the smallest chunks of data read', now() + 5, 3.14159 )
可以像使用任何 SQL 数据库一样编写 SELECT 查询:
文档地址:https://clickhouse.com/docs/zh/tutorial