JenkinsFile
在 Jenkins 中使用 Jenkinsfile 可以通过 API 方式,Jenkinsfile 支持 Groovy语法,写起来非常方便,非常适合“流水线即代码”的实践思路的落地
同时也可以通过 Jenkins 的 BlueOcean 插件来查看流水线,可以更为清晰地进行可视化结果的展示
pipeline
Jenkins Pipeline 实际上是基于 Groovy 实现的 CI/CD 领域特定语言(DSL),主要分为两类,一类叫做 Declarative Pipeline,一类叫做 Scripted Pipeline。
Declarative Pipeline 体验上更接近于我们熟知的 travis CI 的 travis.yml,通过声明自己要做的事情来规范流程,形如:
pipeline {
agent any
stages {
stage('Build') {
steps {
//
}
}
stage('Test') {
steps {
//
}
}
stage('Deploy') {
steps {
//
}
}
}
}
而 Scripted Pipeline 则是旧版本中 Jenkins 支持的 Pipeline 模式,主要是写一些 groovy 的代码来制定流程:
一般情况下声明式的流水线已经可以满足我们的需要,只有在复杂的情况下才会需要脚本式流水线的参与。
过去大家经常在 Jenkins 的界面上直接写脚本来实现自动化,但是现在更鼓励大家通过在项目中增加 Jenkinsfile 的方式把流水线固定下来,实现 Pipeline As Code,Jenkins 的 Pipeline 插件将会自动发现并执行它。
基础语法
Declarative Pipeline 最外层有个 pipeline 表明它是一个声明式流水线,有 4 个主要的部分: agent,post,stages,steps
- Agent
agent 主要用于描述整个 Pipeline 或者指定的 Stage 由什么规则来选择节点执行
Pipeline 级别的 agent 可以视为 Stage 级别的默认值,如果 stage 中没有指定,将会使用与 Pipeline 一致的规则。
在最新的 Jenkins 版本中,可以支持指定任意节点(any),不指定(none),标签(label),节点(node),docker,dockerfile 和 kubernetes 等,具体的配置细节可以查看文档
下面是一个使用 docker 的样例:
agent {
docker {
image 'myregistry.com/node'
label 'my-defined-label'
registryUrl 'https://myregistry.com/'
registryCredentialsId 'myPredefinedCredentialsInJenkins'
args '-v /tmp:/tmp'
}
}
- stages / stage / parallel
Stages 是 Pipeline 中最主要的组成部分,Jenkins 将会按照 Stages 中描述的顺序从上往下的执行。
Stages 中可以包括任意多个 Stage,而 Stage 与 Stages 又能互相嵌套,除此以外还有 parallel 指令可以让内部的 Stage 并行运行。
实际上可以把 Stage 当作最小单元,Stages 指定的是顺序运行,而 parallel 指定的是并行运行。
pipeline {
agent none
stages {
stage('Sequential') {
stages {
stage('In Sequential 1') {
steps {
echo "In Sequential 1"
}
}
stage('In Sequential 2') {
steps {
echo "In Sequential 2"
}
}
stage('Parallel In Sequential') {
parallel {
stage('In Parallel 1') {
steps {
echo "In Parallel 1"
}
}
stage('In Parallel 2') {
steps {
echo "In Parallel 2"
}
}
}
}
}
}
}
}
除了指定 Stage 之间的顺序关系之外,我们还可以通过 when 来指定某个 Stage 指定与否:比如要配置只有在 Master 分支上才执行 push,其他分支上都只运行 build
stages {
stage('Build') {
when {
not { branch 'master' }
}
steps {
sh './scripts/run.py build'
}
}
stage('Run') {
when {
branch 'master'
}
steps {
sh './scripts/run.py push'
}
}
}
还能在 Stage 的级别设置 environment
- Steps
Steps 是 Pipeline 中最核心的部分,每个 Stage 都需要指定 Steps。Steps 内部可以执行一系列的操作,任意操作执行出错都会返回错误。
(1)groovy 语法中有不同的字符串类型,其中 'abc' 是 Plain 字符串,不会转义 ${WROKSPACE} 这样的变量,而 "abc" 会做这样的转换。此外还有 ''' xxx ''' 支持跨行字符串,""" 同理。
(2)调用函数的 () 可以省略,使得函数调用形如 updateGitlabCommitStatus name: 'build', state: 'success',通过 , 来分割不同的参数,支持换行。
(3)可以在声明式流水线中通过 script 来插入一段 groovy 脚本
- Post
post 部分将会在 pipeline 的最后执行,经常用于一些测试完毕后的清理和通知操作。文档中给出了一系列的情况,比较常用的是 always,success 和 failure。
比如说下面的脚本将会在成功和失败的时候更新 gitlab 的状态,在失败的时候发送通知邮件:
post {
failure {
updateGitlabCommitStatus name: 'build', state: 'failed'
emailext body: '$DEFAULT_CONTENT', recipientProviders: [culprits()], subject: '$DEFAULT_SUBJECT'
}
success {
updateGitlabCommitStatus name: 'build', state: 'success'
}
}
每个状态其实都相当于于一个 steps,都能够执行一系列的操作,不同状态的执行顺序是事先规定好的,就是文档中列出的顺序。
Stage 使用
将流水线分按照功能分为逻辑上的三段:构建(Build) 、测试(Test)、部署(Deploy)

pipeline {
agent any
stages {
stage('Build') {
steps {
sh 'echo Build stage ...'
}
}
stage('Test'){
steps {
sh 'echo Test stage ...'
}
}
stage('Deploy') {
steps {
sh 'echo Deploy stage ...'
}
}
}
}
- pipeline 是结构,在其中可以指定 agent 和 stages 等相关信息
- agent 用于指定执行 job 的节点,any 为不做限制
- stages 用与设定具体的 stage
- stage 为具体的节点,比如本文示例中模拟实际的 Build(构建)、测试(Test)、部署(Deploy)的过程,当然实际情况要复杂地多
并行执行的 Stage
上面的例子中将流水线分按照功能分为逻辑上的三段:构建(Build) 、测试(Test)、部署(Deploy)
考虑到实际情况下为了节约持续集成流水线的执行时间,假定实际的构建为三个模块同时进行,后续的测试和部署则是正常方式,结构和顺序如下所示
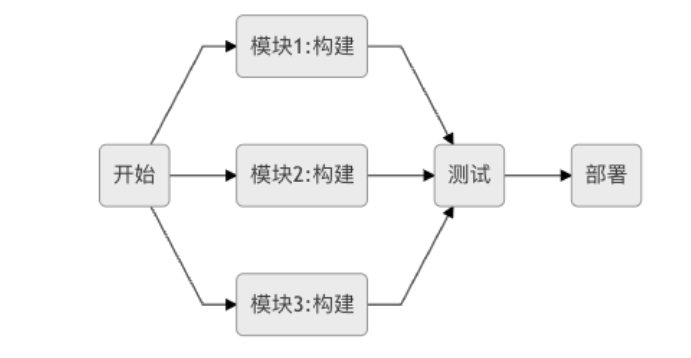
pipeline {
agent any
stages {
stage('Build') {
parallel{
stage('Build:Module1') {
steps {
sh 'echo Build Module1 stage ...'
}
}
stage('Build:Module2') {
steps {
sh 'echo Build Module2 stage ...'
}
}
stage('Build:Module3') {
steps {
sh 'echo Build Module3 stage ...'
}
}
}
}
stage('Test'){
steps {
sh 'echo Test stage ...'
}
}
stage('Deploy') {
steps {
sh 'echo Deploy stage ...'
}
}
}
}
- parallel 中可以列出的任务进行并行操作
带参数的 Job
前文的示例将流水线分按照功能分为逻辑上的三段:构建(Build) 、测试(Test)、部署(Deploy)。这里的示例加入一个 选择输入参数 的过程,然后在后续的节点中对选择的参数的内容进行显示

pipeline {
agent any
parameters {
choice(
description: 'Which Module do you prefer to choose?',
name: 'module_name',
choices: ['Module1', 'Module2', 'Module3']
)
}
stages {
stage('Build') {
steps {
echo "Build stage: Module Selected : ${params.module_name} ..."
}
}
stage('Test'){
steps {
echo "Test stage Module Selected : ${params.module_name} ..."
}
}
stage('Deploy') {
steps {
echo "Deploy stage Module Selected : ${params.module_name} ..."
}
}
}
}
- parameters 块用于定义输入参数名称、输入参数的提示信息以及输入参数的选择初始化内容列表
可以看到,首次执行无需选择参数,缺省选择了 Module1 作为参数
首次执行之后,Job 参数的设定也已经生成;再次执行的时候,输入参数的选择则会生效
参数类型
parameters 这个指令允许我们为一个声明式流水线指定项目参数。这些参数的输入值可以来自一个用户或者一个 API 调用。
下面列举了所有合法的参数类型,以及他们的描述和示例:
booleanParam
是基本的true/false参数。其子参数为name、defaultValue及description。
choice
此参数允许用户从一个选项列表中选择。其子参数为name、choices及description。这里的choices指的是你所输入的以换行符分隔的展示给用户的选项列表。列表中的第一个值会作为默认值。
file
此参数允许用户选择一个文件给流水线使用。其子参数包含fileLocation和description。
已选择的文件位置表明哪里可以用来存放我们选择并上传的文件。这个位置是相对于工作空间而言的相对路径。
string
此参数允许用户输入一个字符串。(它并不会像password参数那样被隐藏起来)。其子参数包括description、defaultValue及name。
text
此参数允许用户输入一个多行文本。其子参数包括name、defaultValue及description
password
此参数允许用户输入一个密码。对于密码,输入的文本被隐藏了起来。可用的子参数包括name、defaultValue及description。
run
此参数允许用户从某个任务中选择一个特定的运行。此参数可能会被用在一个测试环境之中。可用的子参数包括name、project、description及filter。
这个project子参数就是你想让用户从其中选择运行的项目。默认的运行会是最近的一次。无论选择哪个项目,在脚本中你都可以通过一些环境变量访问它们。这些环境变量包括:
· PARAMETER_NAME=<jenkins_url>/job/<job_name>/<run_number>/
· PARAMETER_NAME_JOBNAME=<job_name>
· PARAMETER_NAME_NUMBER=<run_number>
· PARAMETER_NAME_NAME=<display_name>
· PARAMETER_NAME_RESULT=<run_result>
这个filter子参数允许你基于整体的构建状态筛选某类型的运行。可以选择:
· All Builds——包括运行中的构建
· Completed Builds
· Successful Builds——包括稳定和不稳定的构建
· Stable Builds Only