VXLan模式跨主机通信分析
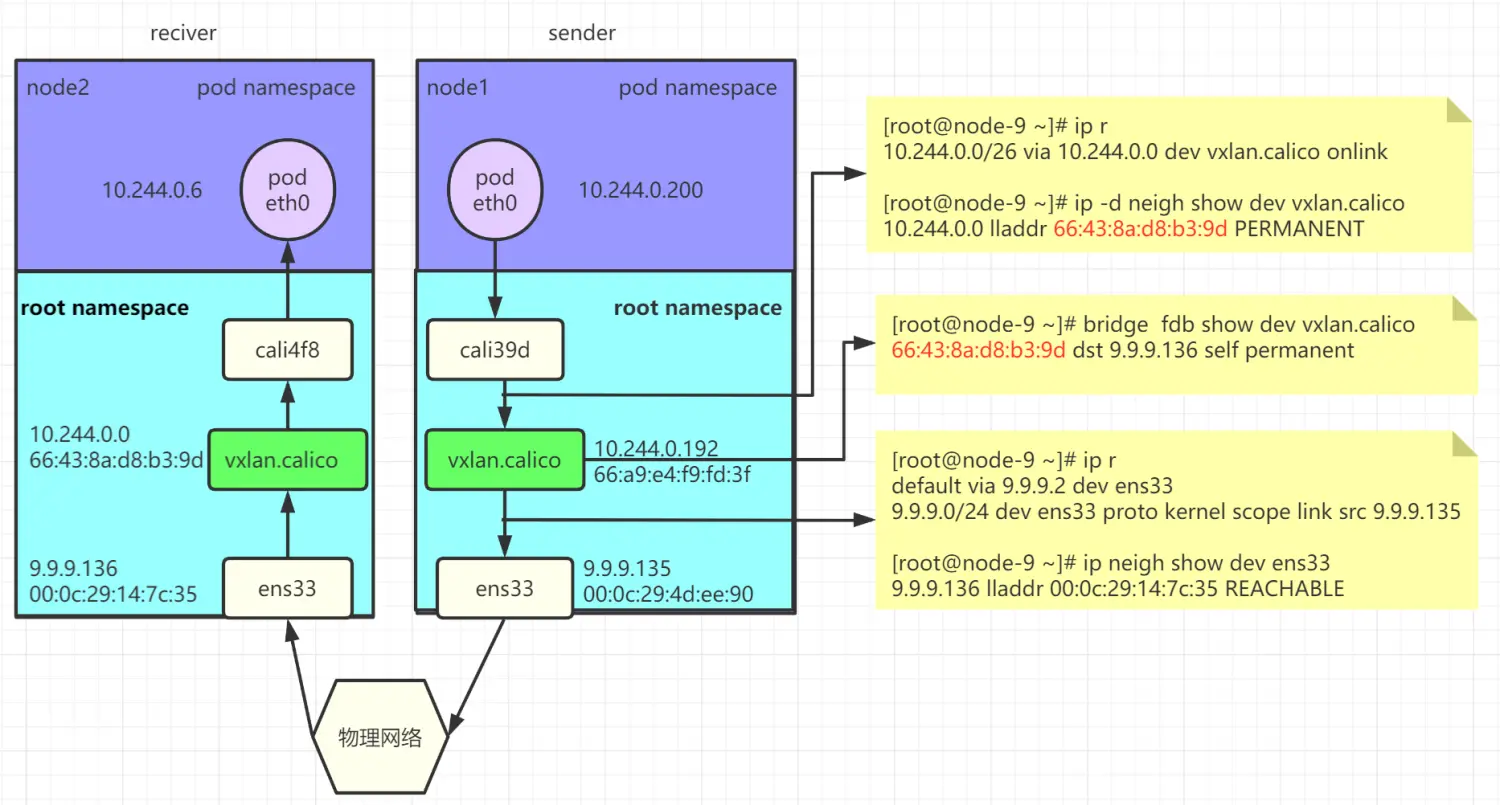
pod 内的 eth0 -> calixx 网卡
参见链接 https://www.jianshu.com/p/75392d686c59
calixxx -> vxlan.calico
calixxx 为容器命名空间内网卡 veth 对的另一端,存在于主机的命名空间内。
calixx 收到二层包之后,向上进行传递。
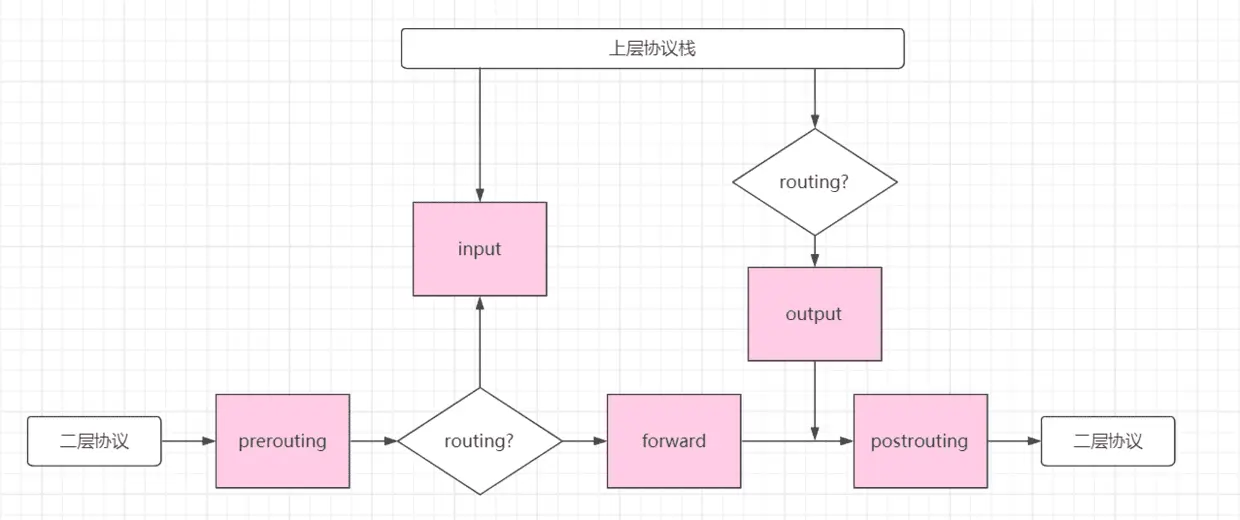
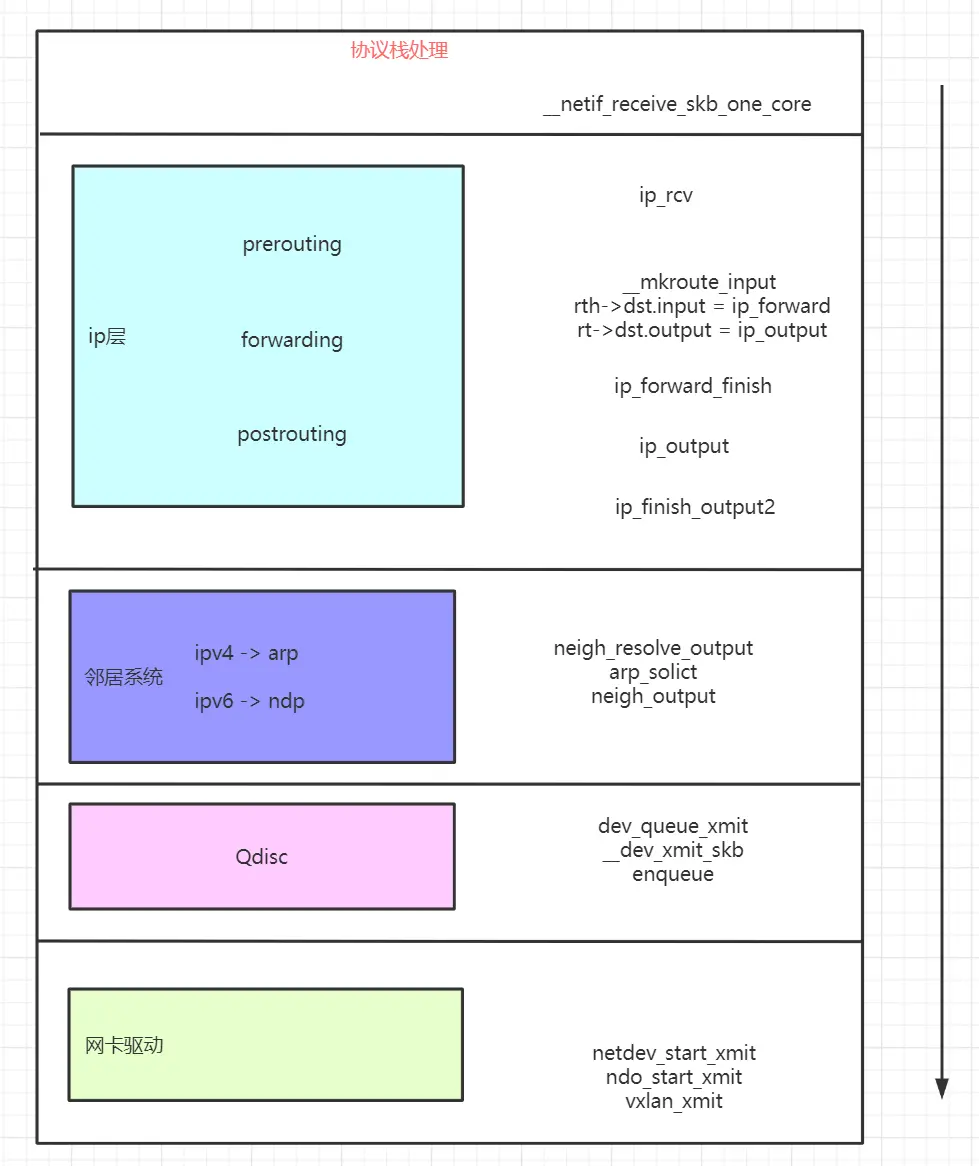
1、 calixx 驱动收到报文后,经过二层处理,经过 ip_rcv 进入 ip 层处理。
2、 通过查找路由,确定了该包需要经过 vxlan.calico 发出去,下一跳的 ip 地址是对端的 vtep 的地址,对端 vtep 的 mac 地址已经由 felix 写入到主机的邻居表项中。
3、 由于已经知道了对端 vtep 设备的 mac 地址,因为这里不再需要进行 mac 地址查询,直接由 neigh_output 交由下层 vxlan 设备处理。
路由条目中的onlink
下一跳是否可达,就是判断下一跳的地址是否在已有的路由中
执行
perf record \
-e probe:fib_check_nh \
-e probe:netlink_recvmsg \
-agR ip r add 5.5.6.0/24 via 4.4.10.2 dev ens192 onlink
代码
// netlink消息的协议处理函数
static const struct proto_ops netlink_ops = {
.family = PF_NETLINK,
.owner = THIS_MODULE,
.release = netlink_release,
.bind = netlink_bind,
.connect = netlink_connect,
.socketpair = sock_no_socketpair,
.accept = sock_no_accept,
.getname = netlink_getname,
.poll = datagram_poll,
.ioctl = netlink_ioctl,
.listen = sock_no_listen,
.shutdown = sock_no_shutdown,
.setsockopt = netlink_setsockopt,
.getsockopt = netlink_getsockopt,
// 内核收到用户态的消息后的处理函数
.sendmsg = netlink_sendmsg,
// 用户读取netlink消息的处理函数
.recvmsg = netlink_recvmsg,
.mmap = sock_no_mmap,
.sendpage = sock_no_sendpage,
};
// 注册增加路由条目的处理函数
rtnl_register(PF_INET, RTM_NEWROUTE, inet_rtm_newroute, NULL, 0);
struct netlink_kernel_cfg cfg = {
.groups = RTNLGRP_MAX,
.input = rtnetlink_rcv,
.cb_mutex = &rtnl_mutex,
.flags = NL_CFG_F_NONROOT_RECV,
.bind = rtnetlink_bind,
};
struct sock *
__netlink_kernel_create(struct net *net, int unit, struct module *module,
struct netlink_kernel_cfg *cfg)
{
if (cfg && cfg->input)
// 修改netlink_rcv 为 rtnetlink_rcv函数
nlk_sk(sk)->netlink_rcv = cfg->input;
}
// 根据perf抓取到的调用栈,继续向下分析
static int netlink_unicast_kernel(struct sock *sk, struct sk_buff *skb,
struct sock *ssk)
{
int ret;
struct netlink_sock *nlk = nlk_sk(sk);
ret = -ECONNREFUSED;
if (nlk->netlink_rcv != NULL) {
ret = skb->len;
netlink_skb_set_owner_r(skb, sk);
NETLINK_CB(skb).sk = ssk;
netlink_deliver_tap_kernel(sk, ssk, skb);
// 这里就调用到了上面的cfg的input函数,即rtnetlink_rcv函数
nlk->netlink_rcv(skb);
consume_skb(skb);
} else {
kfree_skb(skb);
}
sock_put(sk);
return ret;
}
// 处理子模块的消息
static int rtnetlink_rcv_msg(struct sk_buff *skb, struct nlmsghdr *nlh,
struct netlink_ext_ack *extack)
{
link = rtnl_get_link(family, type);
if (flags & RTNL_FLAG_DOIT_UNLOCKED) {
doit = link->doit;
rcu_read_unlock();
// doit就是注册的新增路由表的处理函数inet_rtm_newroute
if (doit)
err = doit(skb, nlh, extack);
module_put(owner);
return err;
}
}
// 对于下一跳的检查函数,内核注释中写明了下一跳很复杂,是由于历史原因,,,
static int fib_check_nh(struct fib_config *cfg, struct fib_nh *nh,
struct netlink_ext_ack *extack)
{
if (nh->nh_gw) {
struct fib_result res;
// 有onlink参数,单独处理
if (nh->nh_flags & RTNH_F_ONLINK) {
dev = __dev_get_by_index(net, nh->nh_oif);
addr_type = inet_addr_type_dev_table(net, dev, nh->nh_gw);
nh->nh_dev = dev;
dev_hold(dev);
nh->nh_scope = RT_SCOPE_LINK;
return 0;
}
// 没有onlink,需要查找下一跳nh是否可达。
{
struct fib_table *tbl = NULL;
struct flowi4 fl4 = {
.daddr = nh->nh_gw,
.flowi4_scope = cfg->fc_scope + 1,
.flowi4_oif = nh->nh_oif,
.flowi4_iif = LOOPBACK_IFINDEX,
};
if (cfg->fc_table)
tbl = fib_get_table(net, cfg->fc_table);
if (tbl)
err = fib_table_lookup(tbl, &fl4, &res,
FIB_LOOKUP_IGNORE_LINKSTATE |
FIB_LOOKUP_NOREF);
if (!tbl || err) {
err = fib_lookup(net, &fl4, &res,
FIB_LOOKUP_IGNORE_LINKSTATE);
}
if (err) {
NL_SET_ERR_MSG(extack,
"Nexthop has invalid gateway");
rcu_read_unlock();
return err;
}
}
}
vxlan 设备到物理网卡
static const struct net_device_ops vxlan_netdev_ether_ops = {
.ndo_init = vxlan_init,
.ndo_uninit = vxlan_uninit,
.ndo_open = vxlan_open,
.ndo_stop = vxlan_stop,
.ndo_start_xmit = vxlan_xmit,
.ndo_get_stats64 = ip_tunnel_get_stats64,
};
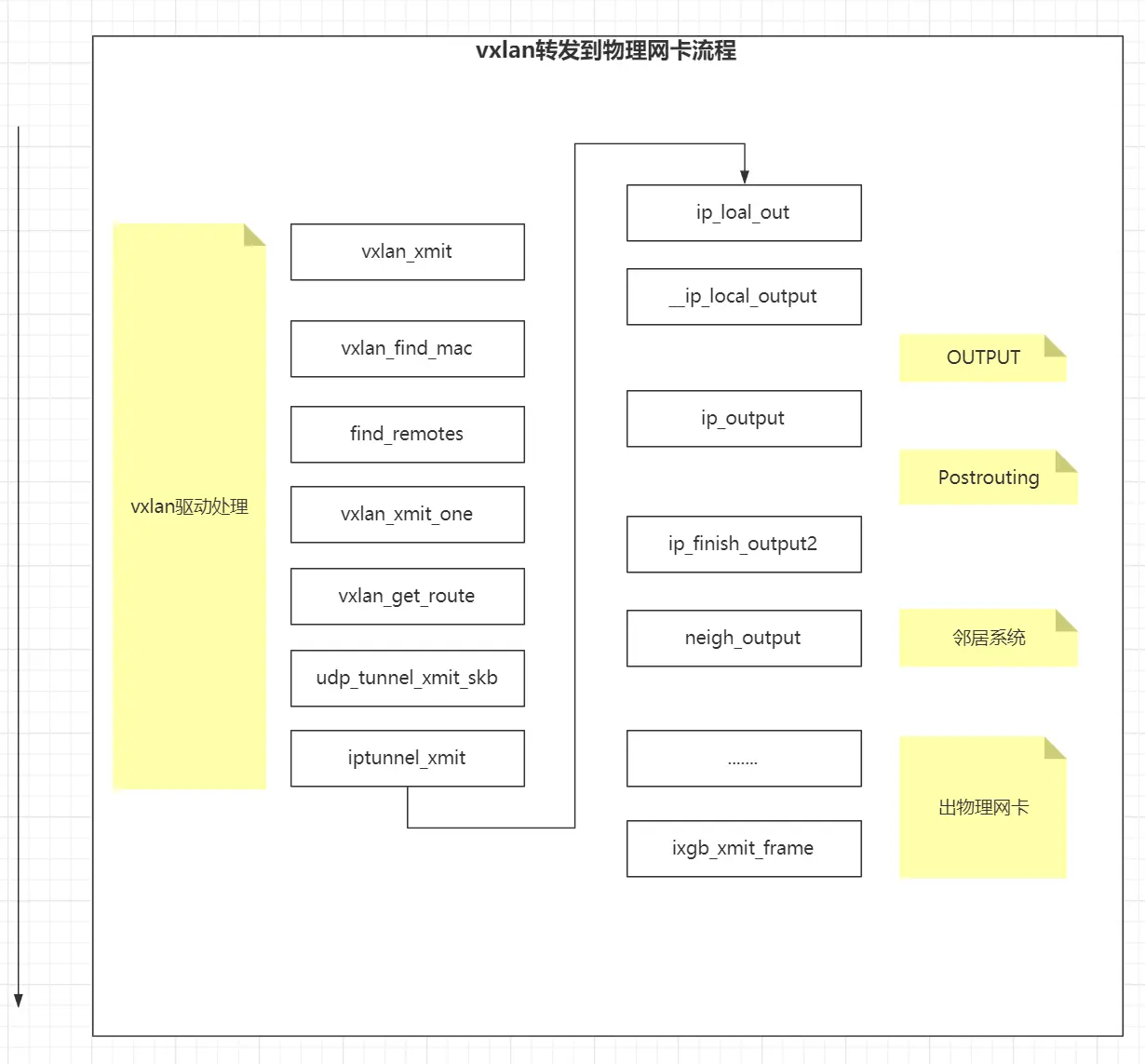
这里这个箭头从下面指到上面并不是画图空间不足,而是为了表现数据包是从二层又回到了三层的处理中。
1、vxlan 设备的转发表中记录了对端 vtep 的 mac 地址和 remoteip 的对应关系。
2、 封装 udp,和 ip 头后,经由 ip_local_out 重新进入 ip 层处理,经过 output 和 postrouting 后,由 ip_finish_output2 出 ip 层。这里要重点理解,vxlan 驱动将上层包伪装成一个要出本机的正常的数据包,由 ip_local_out 进入 ip 层处理,因为 ip_local_out 是一个正常的出本机 udp,tcp 包在 ip 层处理的入口函数。要正确理解 vxlan 设备的封装过程以及 vxlan 设备在这个过程中起到的作用。
3、 经过查询路由,与本机处于同网段,通过 mac 地址查询获取到对端物理网卡的 mac 地址,经由物理网卡发送。如果与本机不在同一网段,则将包交由网关处理。
物理网卡
perf 抓取内核调用栈
在 pod 内 ping 另一台主机上的 pod 的 ip。使用 perf 抓取指定函数的调用堆栈。
perf probe --add iptunnel_xmit
perf probe --add ip_output
perf record -e probe:iptunnel_xmit -e probe:ip_output -ag -F max sleep 10
使用 ftrace 抓取内核调用栈
在 pod 内 ping 另一台主机上的 pod 的 ip。使用 ftrace 抓取指定函数的调用堆栈。
echo iptunnel_xmit > /sys/kernel/debug/tracing/set_ftrace_filter
echo function > /sys/kernel/debug/tracing/current_tracer
echo 1 > /sys/kernel/debug/tracing/options/func_stack_trace
cat /sys/kernel/debug/tracing/trace
<...>-527743 [001] ..s1 98518.998187: iptunnel_xmit <-vxlan_xmit_one
<...>-527743 [001] ..s1 98518.998199: <stack trace>
=> iptunnel_xmit
=> vxlan_xmit_one
=> vxlan_xmit
=> dev_hard_start_xmit
=> __dev_queue_xmit
=> ip_finish_output2
=> ip_output
=> ip_forward
=> ip_rcv
=> __netif_receive_skb_one_core
=> process_backlog
=> net_rx_action
=> __do_softirq
=> do_softirq_own_stack
=> do_softirq
=> __local_bh_enable_ip
=> ip_finish_output2
=> ip_output
=> ip_send_skb
=> raw_sendmsg
=> sock_sendmsg
=> __sys_sendto
=> __x64_sys_sendto
=> do_syscall_64
=> entry_SYSCALL_64_after_hwframe