TypicalWorkloads
CloneSet
CloneSet 控制器是 OpenKruise 提供的对原生 Deployment 的增强控制器,在使用方式上和 Deployment 几乎一致
官方文档:https://openkruise.io/zh/docs/user-manuals/cloneset
如下所示是声明的一个 CloneSet 资源对象:
# cloneset-demo.yaml
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: cs-demo
spec:
replicas: 3
selector:
matchLabels:
app: cs
template:
metadata:
labels:
app: cs
spec:
containers:
- name: nginx
image: nginx:alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
直接创建上面的这个 CloneSet 对象
该对象创建完成后我们可以通过 kubectl describe 命令查看对应的 Events 信息,可以发现 cloneset-controller 是直接创建的 Pod
Deployment 是通过 ReplicaSet 去创建的 Pod,所以从这里也可以看出来 CloneSet 是直接管理 Pod 的
> kubectl describe cloneset cs-demo
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 84s cloneset-controller succeed to create pod cs-demo-jj2qk
Normal SuccessfulCreate 84s cloneset-controller succeed to create pod cs-demo-w2285
Normal SuccessfulCreate 84s cloneset-controller succeed to create pod cs-demo-w7chj
CloneSet 虽然在使用上和 Deployment 比较类似,但还是有非常多比 Deployment 更高级的功能
扩容
CloneSet 在扩容的时候可以通过 ScaleStrategy.MaxUnavailable 来限制扩容的步长,这样可以对服务应用的影响最小,可以设置一个绝对值或百分比,如果不设置该值,则表示不限制
比如在上面的资源清单中添加如下所示数据
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: cs-demo
spec:
minReadySeconds: 60
scaleStrategy:
maxUnavailable: 1
replicas: 5
......
上面配置 scaleStrategy.maxUnavailable 为 1,结合 minReadySeconds 参数,表示在扩容时,只有当上一个扩容出的 Pod 已经 Ready 超过一分钟后,CloneSet 才会执行创建下一个 Pod
比如这里扩容成5个副本,更新上面对象后查看 CloneSet 的事件:
> kubectl describe cloneset cs-demo
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
...
Warning ScaleUpLimited 2m48s cloneset-controller scaleUp is limited because of scaleStrategy.maxUnavailable, limit: 1
Normal SuccessfulCreate 2m48s cloneset-controller succeed to create pod cs-demo-qpwk9
Warning ScaleUpLimited 80s (x7 over 2m48s) cloneset-controller scaleUp is limited because of scaleStrategy.maxUnavailable, limit: 0
Normal SuccessfulCreate 20s cloneset-controller succeed to create pod cs-demo-klrwr
可以看到第一时间扩容了一个 Pod,由于配置了 minReadySeconds: 60,也就是新扩容的 Pod 创建成功超过 1 分钟后才会扩容另外一个 Pod,上面的 Events 信息也能表现出来
查看 Pod 的 AGE 也能看出来扩容的 2 个 Pod 之间间隔了 1 分钟左右:
> kubectl get po
NAME READY STATUS RESTARTS AGE
cs-demo-klrwr 1/1 Running 0 75s
cs-demo-qpwk9 1/1 Running 0 3m43s
..
缩容
当 CloneSet 被缩容时,还可以指定一些 Pod 来删除,这对于 StatefulSet 或者 Deployment 来说是无法实现的, StatefulSet 是根据序号来删除 Pod,而 Deployment/ReplicaSet 目前只能根据控制器里定义的排序来删除
而 CloneSet 允许用户在缩小 replicas 数量的同时,指定想要删除的 Pod 名字,如下所示:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: cs-demo
spec:
minReadySeconds: 60
scaleStrategy:
maxUnavailable: 1
podsToDelete:
- cs-demo-w7chj
replicas: 4
......
更新上面的资源对象后,会将应用缩到 4 个 Pod
如果在 podsToDelete 列表中指定了 Pod 名字,则控制器会优先删除这些 Pod,对于已经被删除的 Pod,控制器会自动从 podsToDelete 列表中清理掉
比如更新上面的资源对象后 cs-demo-79rcx 这个 Pod 会被移除,其余会保留下来:
事件如下:
> kubectl describe cloneset cs-demo
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
...
Normal SuccessfulDelete 6s cloneset-controller succeed to delete pod cs-demo-w7chj
Pod 列表:
> kubectl get po
NAME READY STATUS RESTARTS AGE
cs-demo-jj2qk 1/1 Running 0 23m
cs-demo-klrwr 1/1 Running 0 4m18s
cs-demo-qpwk9 1/1 Running 0 6m46s
cs-demo-w2285 1/1 Running 0 23m
如果只把 Pod 名字加到 podsToDelete,但没有修改 replicas 数量,那么控制器会先把指定的 Pod 删掉,然后再扩一个新的 Pod,另一种直接删除 Pod 的方式是在要删除的 Pod 上打 apps.kruise.io/specified-delete: true 标签
相比于手动直接删除 Pod,使用 podsToDelete 或 apps.kruise.io/specified-delete: true 方式会有 CloneSet 的 maxUnavailable/maxSurge 来保护删除, 并且会触发 PreparingDelete 生命周期的钩子
升级
CloneSet 一共提供了 3 种升级方式:
ReCreate:删除旧 Pod 和它的 PVC,然后用新版本重新创建出来,这是默认的方式InPlaceIfPossible:会优先尝试原地升级 Pod,如果不行再采用重建升级InPlaceOnly:只允许采用原地升级,因此,用户只能修改上一条中的限制字段,如果尝试修改其他字段会被拒绝
这里有一个重要概念:原地升级,这也是 OpenKruise 提供的核心功能之一,当我们要升级一个 Pod 中镜像的时候,下图展示了重建升级和原地升级的区别:
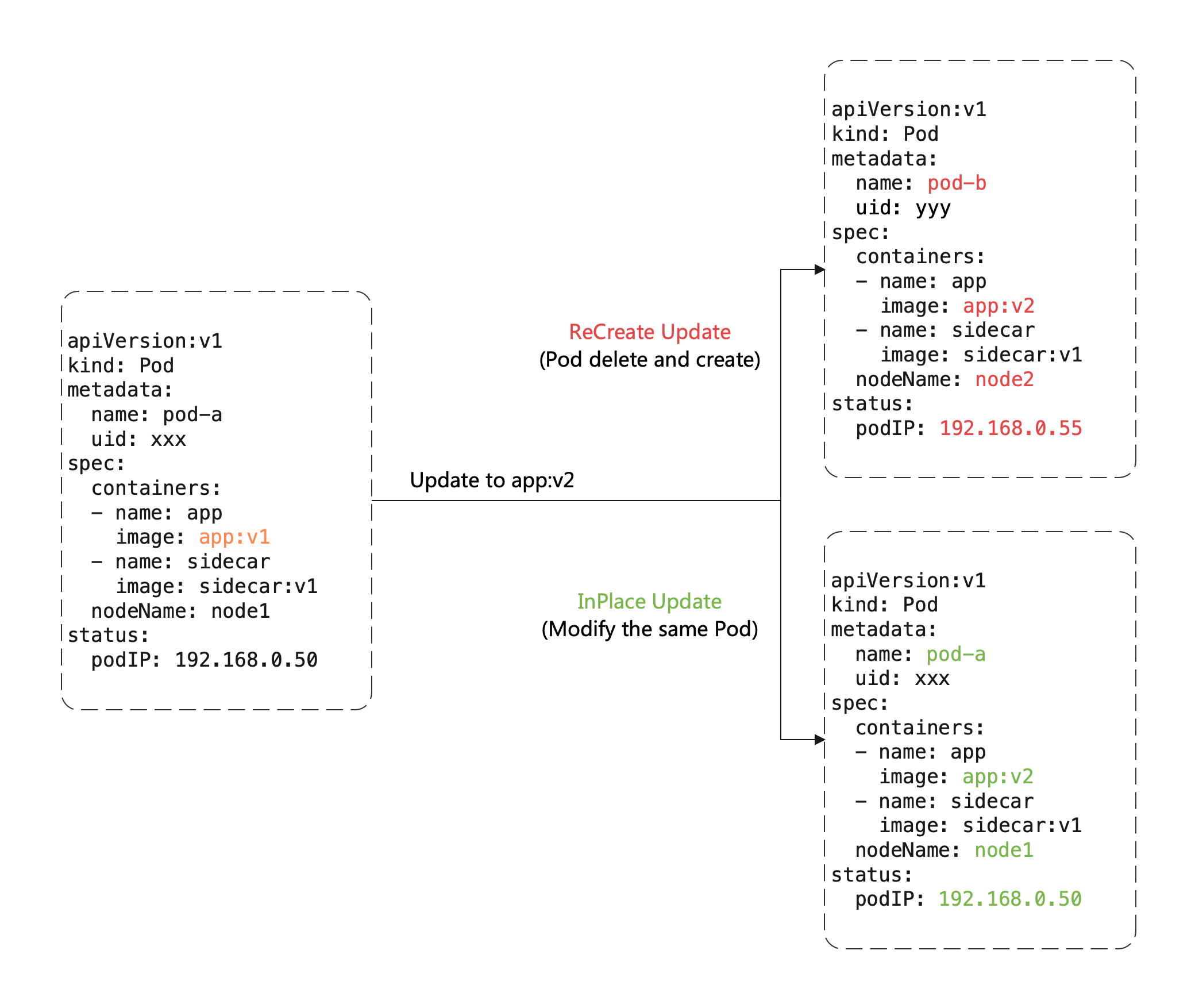
重建升级时需要删除旧 Pod、创建新 Pod:
- Pod 名字和 uid 发生变化,因为它们是完全不同的两个 Pod 对象(比如 Deployment 升级)
- Pod 名字可能不变、但 uid 变化,因为它们是不同的 Pod 对象,只是复用了同一个名字(比如 StatefulSet 升级)
- Pod 所在 Node 名字可能发生变化,因为新 Pod 很可能不会调度到之前所在的 Node 节点
- Pod IP 发生变化,因为新 Pod 很大可能性是不会被分配到之前的 IP 地址
但是对于原地升级,仍然复用同一个 Pod 对象,只是修改它里面的字段:
- 可以避免如调度、分配 IP、挂载盘等额外的操作和代价
- 更快的镜像拉取,因为会复用已有旧镜像的大部分 layer 层,只需要拉取新镜像变化的一些 layer
- 当一个容器在原地升级时,Pod 中的其他容器不会受到影响,仍然维持运行
所以显然如果能用原地升级方式来升级我们的工作负载,对在线应用的影响是最小的
上面提到 CloneSet 升级类型支持 InPlaceIfPossible,这意味着 Kruise 会尽量对 Pod 采取原地升级,如果不能则退化到重建升级,以下的改动会被允许执行原地升级:
- 更新 workload 中的
spec.template.metadata.*,比如 labels/annotations,Kruise 只会将 metadata 中的改动更新到存量 Pod 上 - 更新 workload 中的
spec.template.spec.containers[x].image,Kruise 会原地升级 Pod 中这些容器的镜像,而不会重建整个 Pod - 从 Kruise v1.0 版本开始,更新
spec.template.metadata.labels/annotations并且 container 中有配置 env from 这些改动的labels/anntations,Kruise 会原地升级这些容器来生效新的 env 值
否则,其他字段的改动,比如 spec.template.spec.containers[x].env 或 spec.template.spec.containers[x].resources,都是会回退为重建升级
比如将上面的应用升级方式设置为 InPlaceIfPossible,只需要在资源清单中添加 spec.updateStrategy.type: InPlaceIfPossible 即可
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: cs-demo
spec:
updateStrategy:
type: InPlaceIfPossible
...
containers:
- name: nginx
image: 'nginx:1.7.9'
更新后可以发现 Pod 的状态并没有发生什么大的变化,名称、IP 都一样,唯一变化的是镜像 tag:
> kubectl get po
NAME READY STATUS RESTARTS AGE
cs-demo-jj2qk 1/1 Running 1 (2s ago) 37m
cs-demo-klrwr 1/1 Running 1 (4m47s ago) 18m
cs-demo-qpwk9 1/1 Running 1 (3m22s ago) 21m
cs-demo-w2285 1/1 Running 1 (65s ago) 37m
> kubectl describe po cs-demo-klrwr
...
Containers:
nginx:
Container ID: containerd://7fd2e81bb42d0959664a4746df72fef58e962fd5c5a992787ed434671ffd4eee
Image: nginx:1.7.9
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 15m default-scheduler Successfully assigned default/cs-demo-klrwr to devnode1
Normal Pulled 15m kubelet Container image "nginx:alpine" already present on machine
Normal Killing 89s kubelet Container nginx definition changed, will be restarted
Normal Pulling 89s kubelet Pulling image "nginx:1.7.9"
Normal Created 70s (x2 over 15m) kubelet Created container nginx
Normal Started 70s (x2 over 15m) kubelet Started container nginx
Normal Pulled 70s kubelet Successfully pulled image "nginx:1.7.9" in 18.674993118s (18.674995489s including waiting)
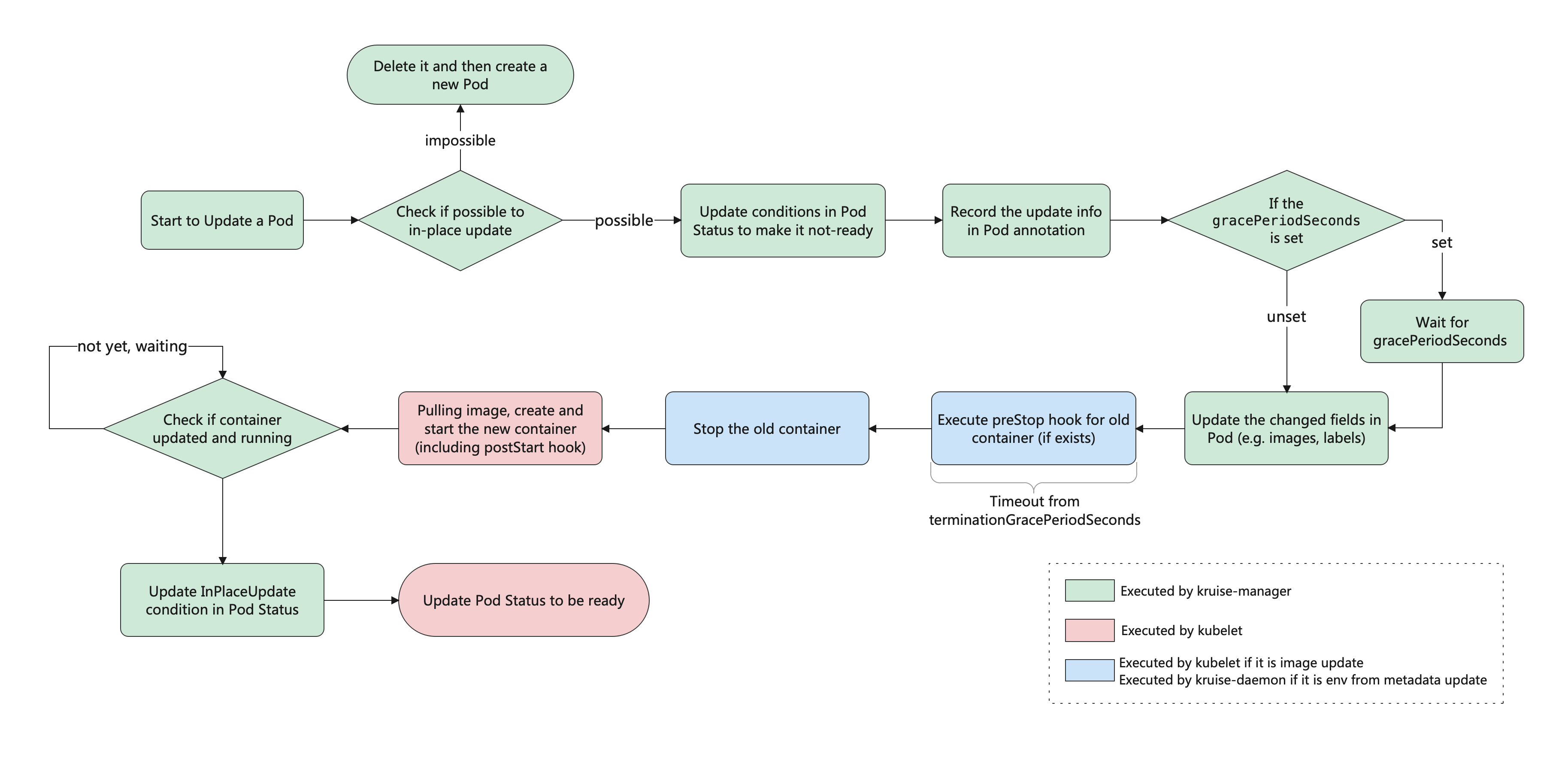
这就是原地升级的效果,原地升级整体工作流程如下图所示:
预热灰度发布新镜像
如果在安装或升级 Kruise 的时候启用了 PreDownloadImageForInPlaceUpdate 这个 feature-gate,CloneSet 控制器会自动在所有旧版本 pod 所在节点上预热正在灰度发布的新版本镜像,这对于应用发布加速很有帮助
默认情况下 CloneSet 每个新镜像预热时的并发度都是 1,也就是一个个节点拉镜像,如果需要调整,你可以在 CloneSet annotation 上设置并发度:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
annotations:
apps.kruise.io/image-predownload-parallelism: "5"
注意,为了避免大部分不必要的镜像拉取,目前只针对
replicas > 3的 CloneSet 做自动预热
分批进行灰度
CloneSet 还支持分批进行灰度
在 updateStrategy 属性中可以配置 partition 参数,该参数可以用来保留旧版本 Pod 的数量或百分比,默认为 0:
- 如果是数字,控制器会将
(replicas - partition)数量的 Pod 更新到最新版本 - 如果是百分比,控制器会将
(replicas * (100% - partition))数量的 Pod 更新到最新版本
比如,将上面示例中的的 image 更新为 nginx:latest 并且设置 partition=2,更新镜像后,过一会查看可以发现只升级了 2 个 Pod:
> kubectl get po
NAME READY STATUS RESTARTS AGE
cs-demo-jj2qk 1/1 Running 2 (22s ago) 43m
cs-demo-klrwr 1/1 Running 1 (10m ago) 23m
cs-demo-qpwk9 1/1 Running 1 (8m46s ago) 26m
cs-demo-w2285 1/1 Running 2 (21s ago) 43m
> kubectl describe po cs-demo-jj2qk | grep "Image:"
Image: nginx:alpine
> kubectl describe po cs-demo-klrwr | grep "Image:"
Image: nginx:1.7.9
其他
此外 CloneSet 还支持一些更高级的用法,比如可以定义优先级策略来控制 Pod 发布的优先级规则,还可以定义策略来将一类 Pod 打散到整个发布过程中,也可以暂停 Pod 发布等操作
Advanced StatefulSet
该控制器在原生的 StatefulSet 基础上增强了发布能力,比如 maxUnavailable 并行发布、原地升级等,该对象的名称也是 StatefulSet,但是 apiVersion 是 apps.kruise.io/v1beta1
这个 CRD 的所有默认字段、默认行为与原生 StatefulSet 完全一致,除此之外还提供了一些 optional 字段来扩展增强的策略
用户从原生 StatefulSet 迁移到 Advanced StatefulSet,只需要把 apiVersion 修改后提交即可:
- apiVersion: apps/v1
+ apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: sample
spec:
#...
最大不可用
Advanced StatefulSet 在滚动更新策略中新增了 maxUnavailable 来支持并行 Pod 发布,它会保证发布过程中最多有多少个 Pod 处于不可用状态
注意,maxUnavailable 只能配合 podManagementPolicy 为 Parallel 来使用
这个策略的效果和 Deployment 中的类似,但是可能会导致发布过程中的 order 顺序不能严格保证,如果不配置 maxUnavailable,它的默认值为 1,也就是和原生 StatefulSet 一样只能串行发布 Pod,即使把 podManagementPolicy 配置为 Parallel 也是这样
比如现在创建一个如下所示的 Advanced StatefulSet:
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: web
namespace: default
spec:
serviceName: "nginx-headless"
podManagementPolicy: Parallel
replicas: 5
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 3
# partition: 4
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- name: web
containerPort: 80
直接创建该对象,由于对象名称也是 StatefulSet,所以不能直接用 get sts 来获取了,要通过 get asts 获取:
该应用下有 5 个 Pod,假设应用能容忍 3 个副本不可用,当把 StatefulSet 里的 Pod 升级版本的时候,可以通过以下步骤来做:
- 设置 maxUnavailable=3
- (可选) 如果需要灰度升级,设置 partition=4,Partition 默认的意思是 order 大于等于这个数值的 Pod 才会更新,在这里就只会更新 P4,即使我们设置了 maxUnavailable=3。
- 在 P4 升级完成后,把 partition 调整为 0,此时,控制器会同时升级 P1、P2、P3 三个 Pod。注意,如果是原生 StatefulSet,只能串行升级 P3、P2、P1
- 一旦这三个 Pod 中有一个升级完成了,控制器会立即开始升级 P0
比如这里把上面应用的镜像版本进行修改,更新后查看 Pod 状态,可以看到有3个 Pod 并行升级的: